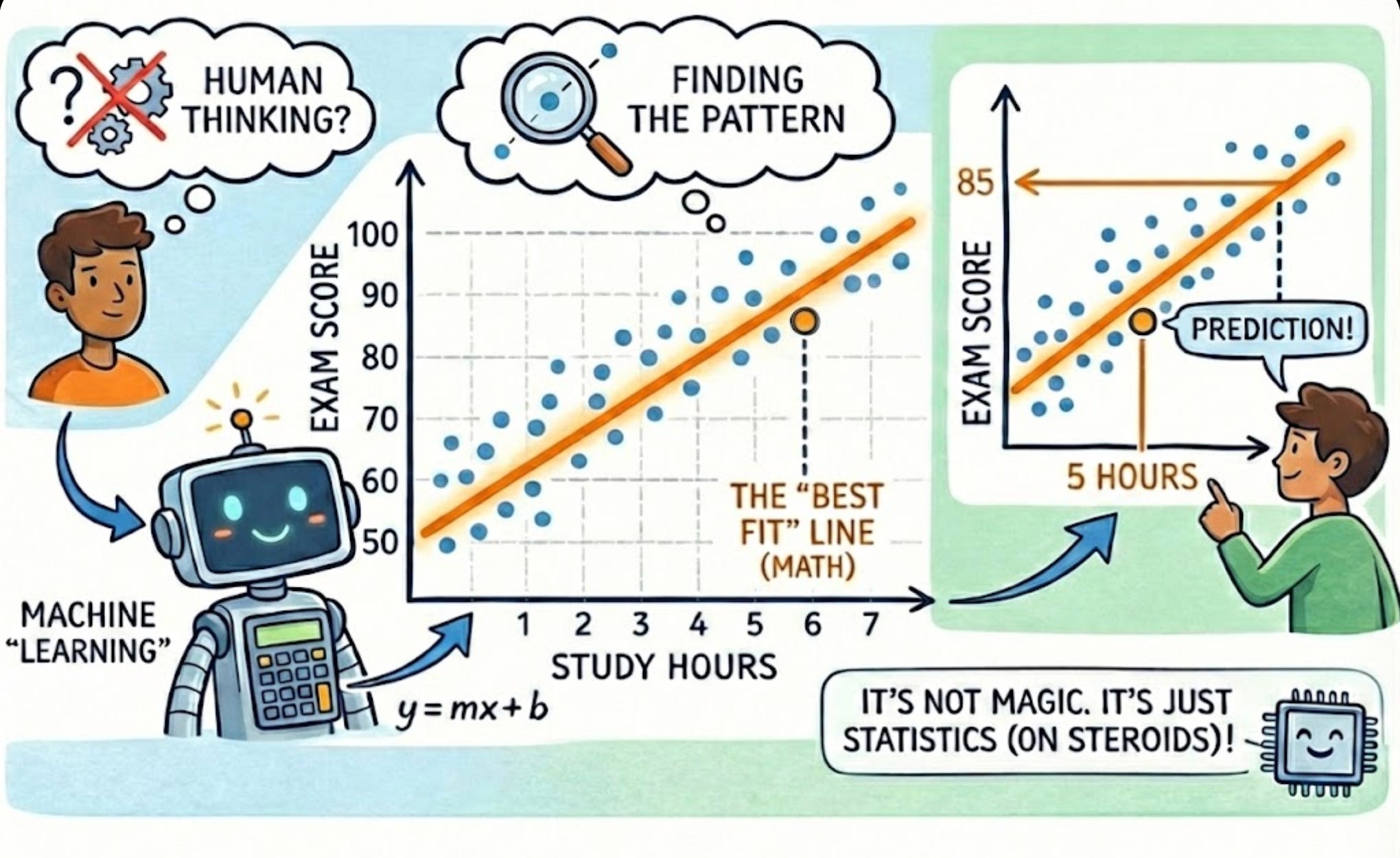
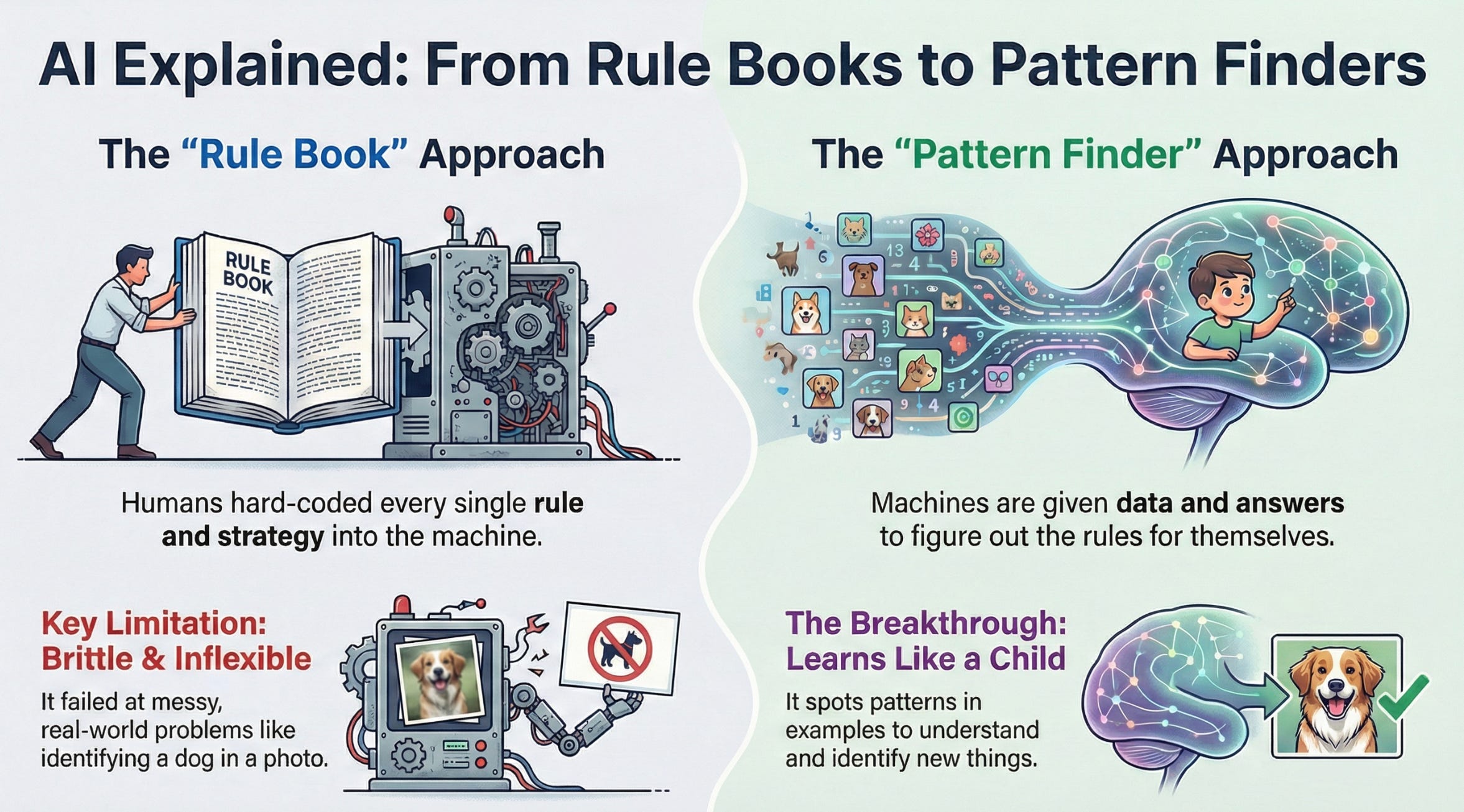
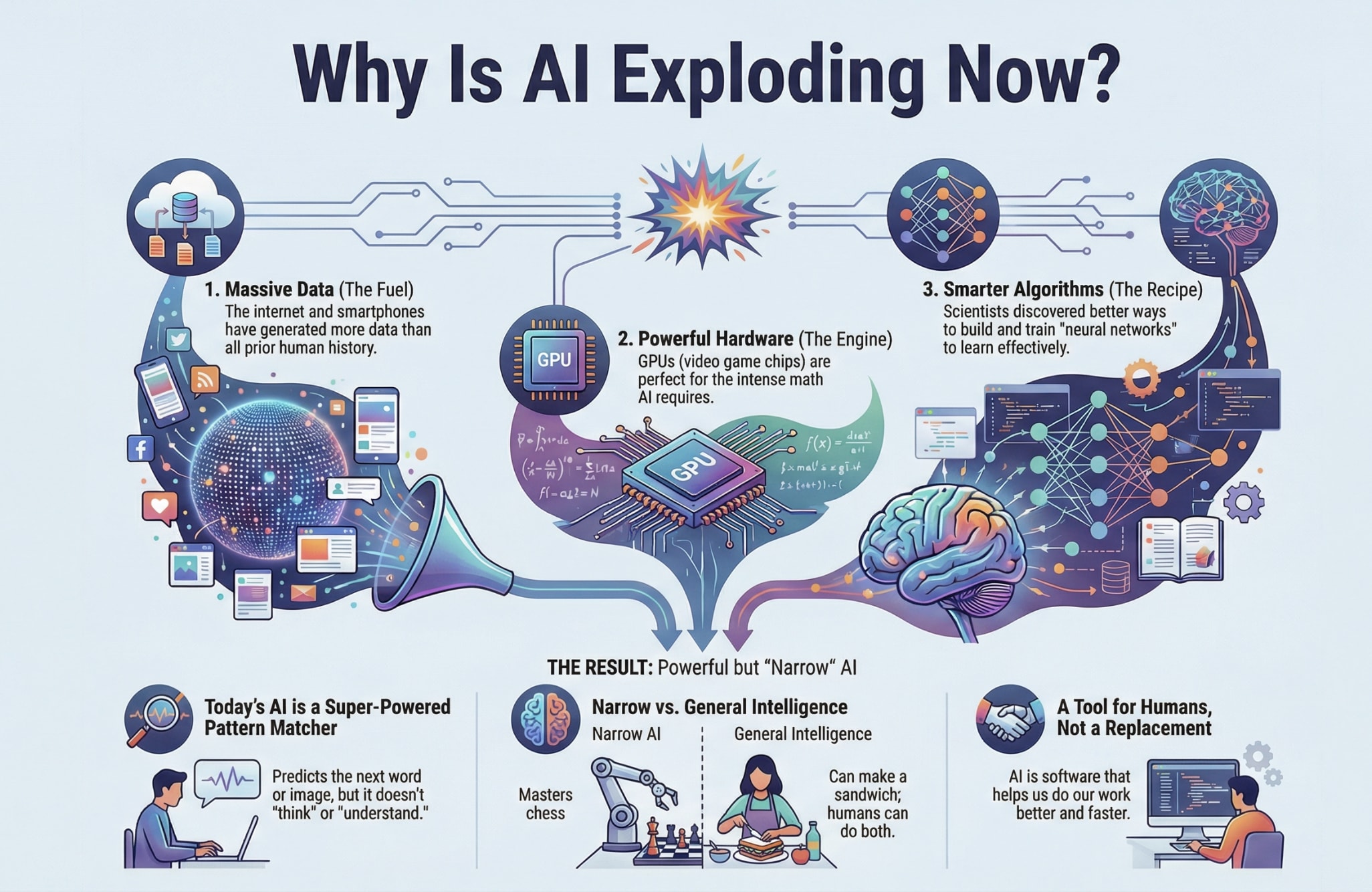
Data Science is using scientific methods and tools to extract useful insights from data. It’s the process of turning raw information into decisions – like a doctor diagnosing a patient’s health using symptoms, tests, and medical history.
AI for Common Folks
Jan 26, 2026
Hey Common Folks!
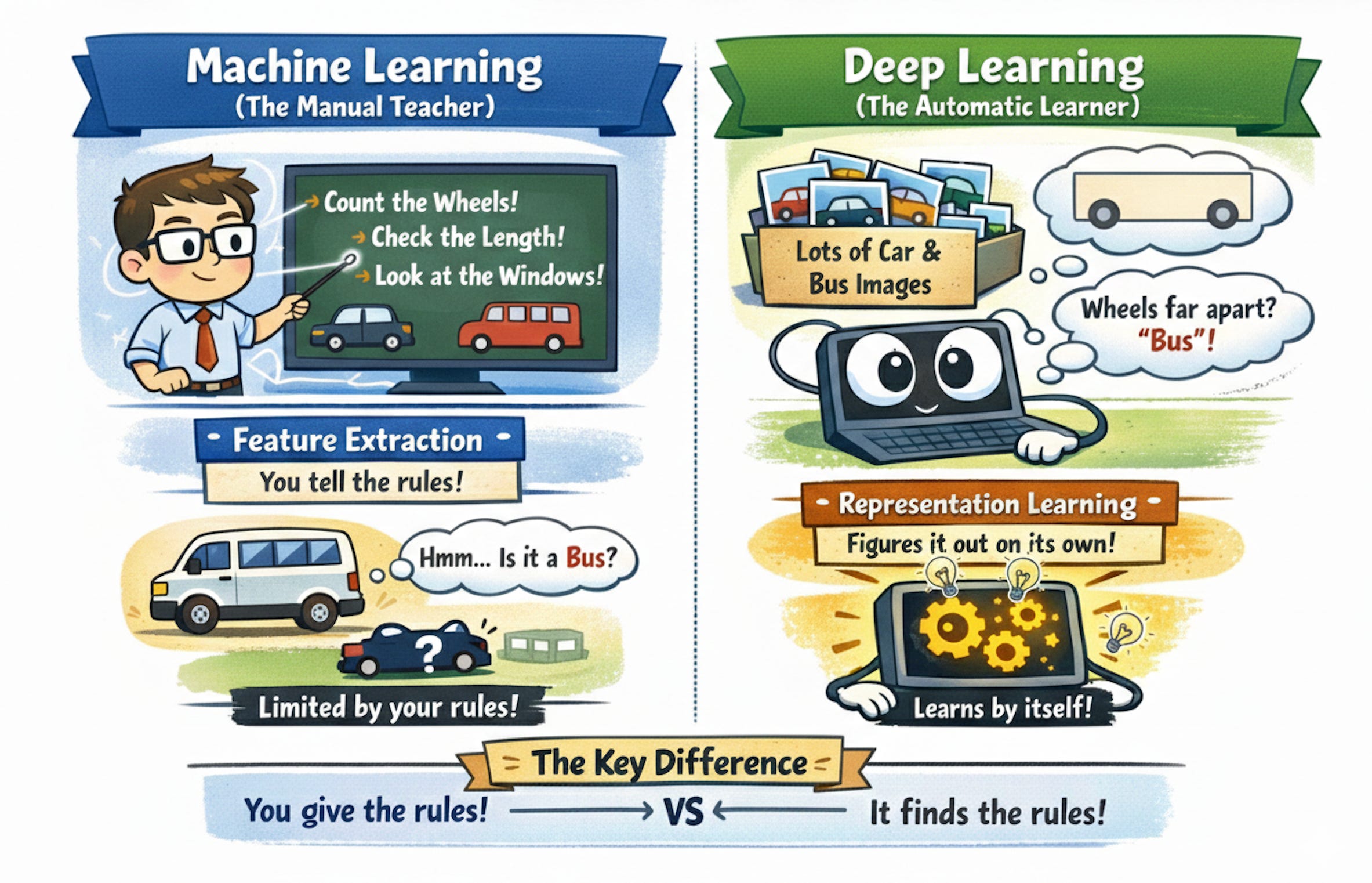
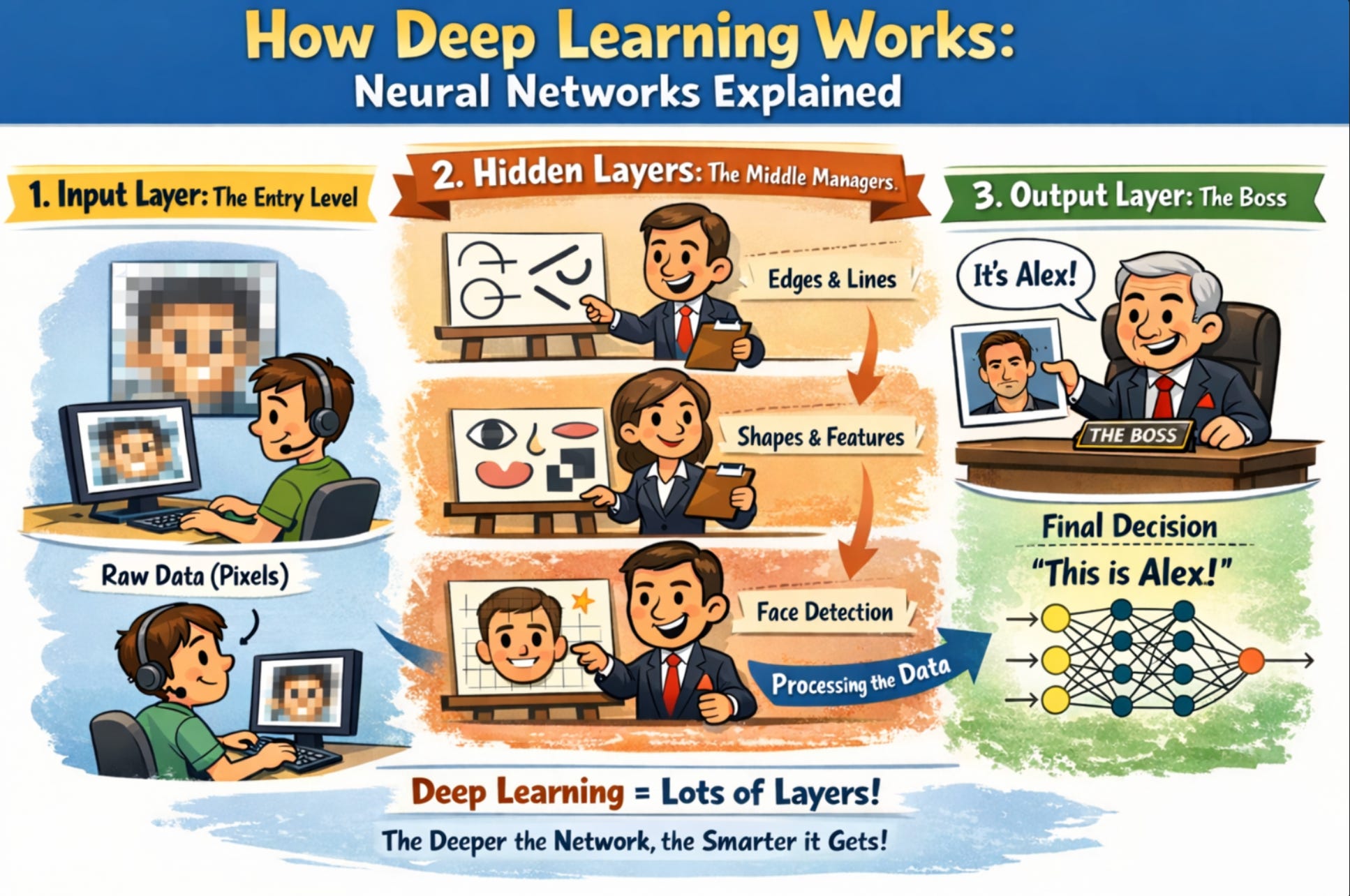
We’ve talked about the “brain” (AI), the “learning engine” (Machine Learning), and the “complex neural wiring” (Deep Learning).
But today, we are zooming out to look at the entire hospital where all this diagnosis and treatment happens. We are talking about Data Science.
You’ve heard the phrase “Data is the new oil.” It’s a cliché, but it’s true. However, crude oil sitting in the ground is worthless. You need to refine it into gasoline, plastic, and jet fuel before it powers anything.
Data Science is that refinery. It is the process of taking raw, messy information and turning it into gold.
What Is Data Science?
Data Science is the field of using scientific methods, algorithms, and systems to extract knowledge and insights from data—both structured (like spreadsheets) and unstructured (like customer reviews or images).
Think of it this way: Data Science is like being a doctor for organizations.
The Doctor Analogy
Imagine you’re not feeling well and you visit a doctor. Here’s what happens:
1. Symptoms (The Problem)
You tell the doctor: “I’m always tired, constantly thirsty, and losing weight.”
→ In business: “Our sales are dropping,” “Customers are leaving,” “The machine keeps breaking.”
2. Medical History (Historical Data)
The doctor asks: “When did this start? Has it happened before? Any family history?”
→ In Data Science: You look at past performance, previous issues, patterns over time.
3. Running Tests (Data Collection)
The doctor orders blood tests, X-rays, maybe an MRI—gathering evidence.
→ In Data Science: You pull data from databases, surveys, sensors, website logs, customer calls.
4. Diagnosis (Data Analysis)
The doctor analyzes all the test results and finds the root cause: “You have Type 2 diabetes.”
→ In Data Science: “Your sales are dropping because new customers aren’t returning after their first purchase.”
5. Treatment Plan (The Model/Solution)
The doctor prescribes medication, lifestyle changes, and a monitoring plan.
→ In Data Science: You build a model or create a strategy—”Send personalized follow-up emails to first-time buyers within 48 hours.”
6. Monitoring & Follow-up (Deployment & Evaluation)
The doctor checks: “Are your blood sugar levels improving? Do we need to adjust the medication?”
→ In Data Science: “After implementing the email campaign, did repeat purchases actually increase?”
7. Explaining to the Patient (Communication)
A good doctor doesn’t just write a prescription—they explain what’s wrong, why it happened, and how the treatment works.
→ A good Data Scientist translates complex findings into plain English for executives: “If we fix the onboarding experience, we’ll retain 20% more customers—that’s $500K in annual revenue.”
Data Science uses AI and Machine Learning as tools, but it also involves statistics, visualization, domain expertise, and a lot of human judgment.
The “Secret Sauce” Ingredients
Data Science isn’t just one skill; it’s a mix of three things:
1. Computer Science (The Tech Skills)
You need to code to handle massive amounts of information. Python and SQL are the most common languages. You don’t need to be a software engineer—just comfortable enough to wrangle data and automate analysis.
2. Math & Statistics (The Logic Skills)
You need to know if the patterns you see are real or just random luck. This is where statistics comes in—understanding averages, probabilities, correlations, and whether results are statistically significant.
3. Domain Knowledge (The Real-World Skills)
This is crucial and often underrated. If you’re analyzing cricket data, you need to know what a “run rate” is. If you’re analyzing cancer data, you need to know biology. The best insights come when you combine technical skills with subject-matter expertise.
Just like a doctor needs to know medicine (domain knowledge), anatomy (science), and how to use medical equipment (tools)—a Data Scientist needs all three ingredients.
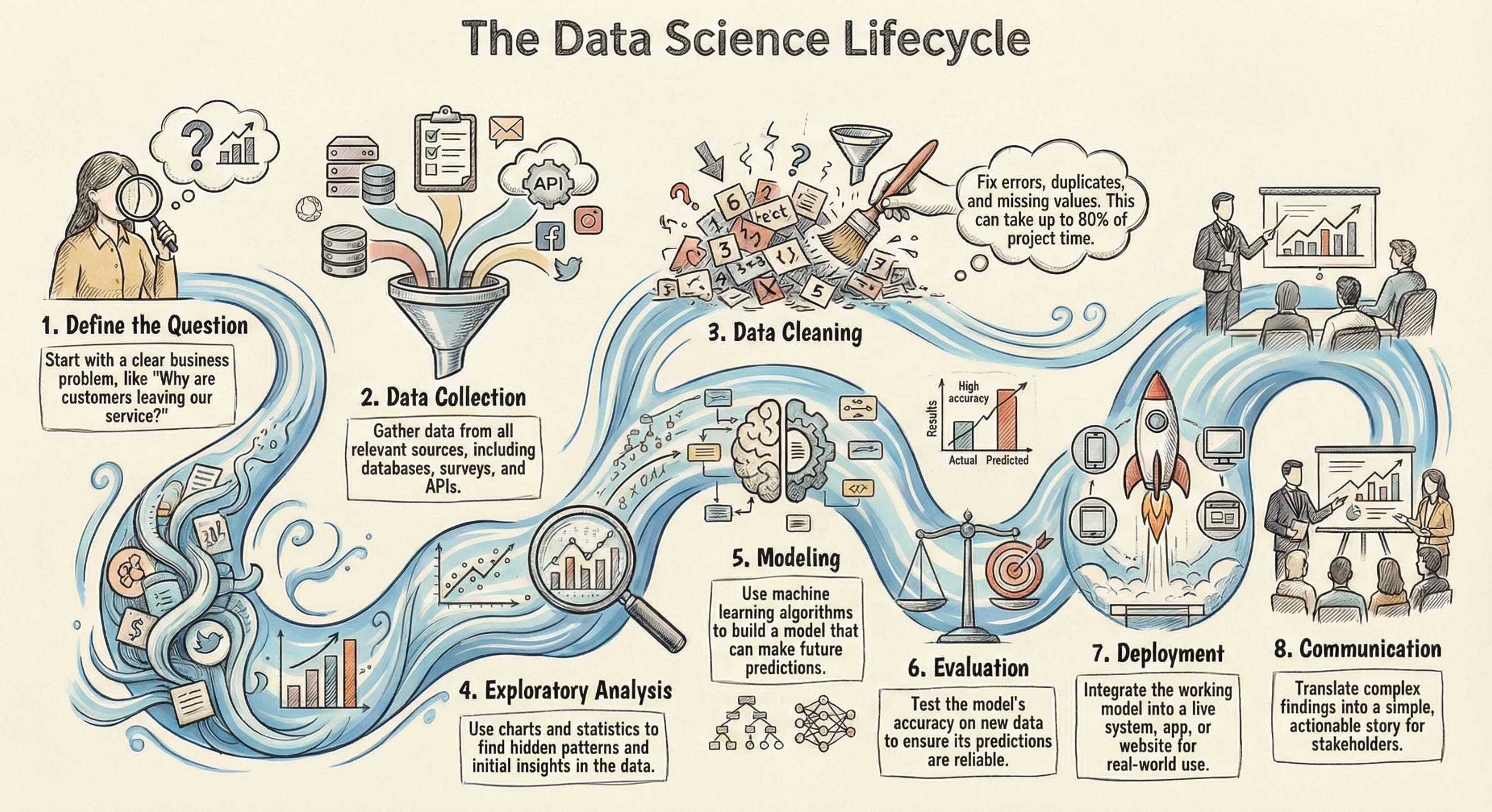
How Does It Actually Work? (The Lifecycle)
Data Science isn’t just “running code.” It’s a lifecycle. Based on how experts break it down, here’s what happens behind the scenes:
1. Define the Question (The Symptoms)
Before touching any data, you need a clear question:
-
“Why are customers leaving our service?”
-
“Which patients are at highest risk for complications?”
-
“What causes this factory machine to break down?”
No question = no direction. This step sounds obvious, but most failed data projects skip it.
2. Data Collection (Running the Tests)
You gather data from databases, spreadsheets, APIs, sensors, surveys—anywhere relevant information exists.
Example: A retail company investigating falling sales might collect:
3. Data Cleaning (The Janitor Work)
Real data is messy. It has missing values, typos, duplicates, and errors. This unglamorous step takes 60-80% of a Data Scientist’s time.
Example:
One customer entered their age as “25,” another as “Twenty-Five,” a third accidentally typed “250,” and a fourth left it blank. A Data Scientist has to fix all of this before the computer can use it.
The saying in the field: “Garbage In, Garbage Out.” If you feed bad data into a model, you get bad predictions—just like a doctor making the wrong diagnosis from contaminated lab samples.
4. Exploratory Data Analysis (Finding Patterns)
This is where you “interview” the data by creating graphs, charts, and statistical summaries to find hidden patterns.
You might discover:
-
Ice cream sales spike when sunglasses sales spike (both driven by summer weather)
-
Customers who spend 10+ minutes on your website are 5x more likely to buy
-
Machine breakdowns happen more often on night shifts
This is like a doctor noticing your symptoms all point toward one condition.
5. Modeling (Creating the Treatment Plan)
This is where Machine Learning often comes in. You feed clean data into an algorithm to create a model—a mathematical formula that can make predictions.
Examples:
-
Predict which customers will cancel their subscription next month
-
Forecast how many flu cases a hospital will see this winter
-
Recommend which movie you’ll watch next on Netflix
Just like a doctor prescribes treatment based on medical evidence and past cases, a Data Scientist builds models based on historical patterns.
6. Evaluation (Does the Treatment Work?)
Just because a model makes predictions doesn’t mean they’re accurate. You test it on new data to see how well it performs.
If your model predicts 100 customers will leave but only 10 actually do, that’s a problem. Back to the drawing board—just like adjusting medication that isn’t working.
7. Deployment (Putting It Into Action)
Once the model works, you deploy it—meaning you put it into an app, website, or system where it runs automatically in the real world.
Examples:
-
Credit card companies use fraud detection models in real-time
-
Spotify’s recommendation algorithm runs every time you open the app
-
Self-driving cars use models to recognize stop signs
8. Communication (Explaining to the Patient)
The final step—and another underrated one—is explaining your findings to people who don’t speak “data.”
A great Data Scientist takes complex analysis and turns it into a simple, actionable story:
“If we send discount emails to customers who haven’t purchased in 30 days, we’ll recover 15% of them—that’s $200K in revenue. Here’s a simple chart showing the pattern.”
Charts, visuals, and plain English matter just as much as the code. It’s like a doctor explaining your diagnosis so you actually understand and follow the treatment plan.
Data Science in Your Daily Life
You interact with Data Science dozens of times every day, whether you realize it or not. Here are three real-world examples:
1. The “Diapers and Beer” Phenomenon (Retail)
Supermarkets use Data Science for Association Rule Learning (finding what items are bought together).
A famous example: stores discovered that men who bought diapers on Friday evenings often bought beer too.
The Diagnosis: Dad is tired, picking up supplies for the baby, and grabbing a treat for himself.
The Treatment: The store places beer right next to the diapers. Sales go up.
That’s Data Science—finding unexpected patterns and turning them into profit.
2. Uber’s Surge Pricing (Transportation)
Ever wonder why your Uber costs more when it’s raining? It’s not just greed—it’s a Data Science model balancing supply and demand in real-time.
The model predicts:
“It’s raining in downtown. Demand will spike 40%. Supply is low. Temporarily increase price to encourage more drivers to get on the road.”
Just like a doctor adjusting medication dosage based on how your body responds, Uber’s algorithm adjusts prices based on real-time conditions.
3. Who Gets the Loan? (Banking)
When you apply for a loan, a bank officer doesn’t just look at your face. They feed your data—age, salary, credit score, past debts, employment history—into a model.
The model compares you to thousands of past customers:
This is Credit Risk Assessment—a classic Data Science application that protects both the bank and borrowers.
The “Confusing” Job Titles
You will hear different job titles thrown around. Here is the cheat sheet:
Data Engineer (The Lab Technician)
Builds the “pipes” and infrastructure to move data from sources (databases, apps, sensors) into storage systems. They make sure data is available, clean, and flowing properly—like a lab tech ensuring all equipment is working and samples are properly prepared.
Data Analyst (The Diagnostician)
Looks at the data to tell you what happened in the past.
Example: “Sales dropped 10% last month in the Midwest region.”
Think of them as the specialist running initial tests and reporting findings.
Data Scientist (The Treatment Planner)
Looks at the data to tell you what will happen in the future or what you should do.
Example: “If we don’t change the price, sales will drop another 15% next quarter. But if we offer a limited-time bundle, we can reverse the trend.”
They’re like the doctor who diagnoses AND prescribes the treatment.
Machine Learning Engineer (The Specialist Surgeon)
Takes models created by Data Scientists and turns them into production systems that run at scale. They ensure the “treatment” works reliably for millions of “patients” simultaneously.
The Takeaway
Data Science is the bridge between raw numbers and real-world decisions.
-
AI is the engine.
-
Machine Learning is the transmission.
-
Data Science is the car, the driver, and the map—getting you to your destination.
It turns the chaos of customer reviews into product improvements.
It turns patient medical records into life-saving diagnoses.
It turns website clicks into personalized recommendations.
It turns noise into knowledge.
The best part? You don’t need a PhD to understand the concepts or use Data Science thinking in your own work. The mindset—asking good questions, looking for patterns, testing ideas with data—is something anyone can learn.
Just like you don’t need to be a doctor to understand when you need medical care, you don’t need to be a Data Scientist to recognize when data could solve your problem.
Was this helpful? Reply and let us know what Data Science concept confuses you the most!
AI for Common Folks — Understand AI in plain English.