Pre-training is the process of teaching an AI model general knowledge from a massive dataset before teaching it any specific job. It is the heavy lifting that turns a blank computer brain into a knowledgeable generalist.
Hey Common Folks!
Yesterday we covered tokens — how AI breaks your prompt into the small pieces it can actually read. Now we answer the question that opens up right underneath that one: where did AI learn what those tokens actually mean in the first place?
The answer is Pre-training. It is the “P” in GPT (Generative Pre-trained Transformer). It is the phase where a Foundation Model learns 99% of everything it knows, and it is the reason today’s AI is so shockingly capable, and occasionally so shockingly confident about things it shouldn’t be.
What is Pre-training?
Think of it as General Education. Before you become a doctor, an accountant, or a coder, you first have to learn the alphabet, how to read, how to do basic math, and how the world works. You don’t start kindergarten by performing brain surgery.
Pre-training is the AI version of that long, broad foundation phase. The model spends an enormous amount of time learning general knowledge before anyone ever asks it to do a specific job.
The Problem: Learning from Scratch is Hard
Why do we even need pre-training? Why can’t we just teach an AI to answer customer support emails directly?
Because deep learning models are data hungry. If you want to train a model from scratch to recognize a cat, you need thousands of photos of cats. But not just photos — you need humans to manually label them: “This is a cat,” “This is a dog.” That labeling process is slow, expensive, and tedious.
And if you tried to teach a computer to understand English by only showing it customer support emails, it would fail. It wouldn’t know what a verb is, what “angry” sounds like, or even how to structure a sentence.
You can’t shortcut the foundation. You have to build it.
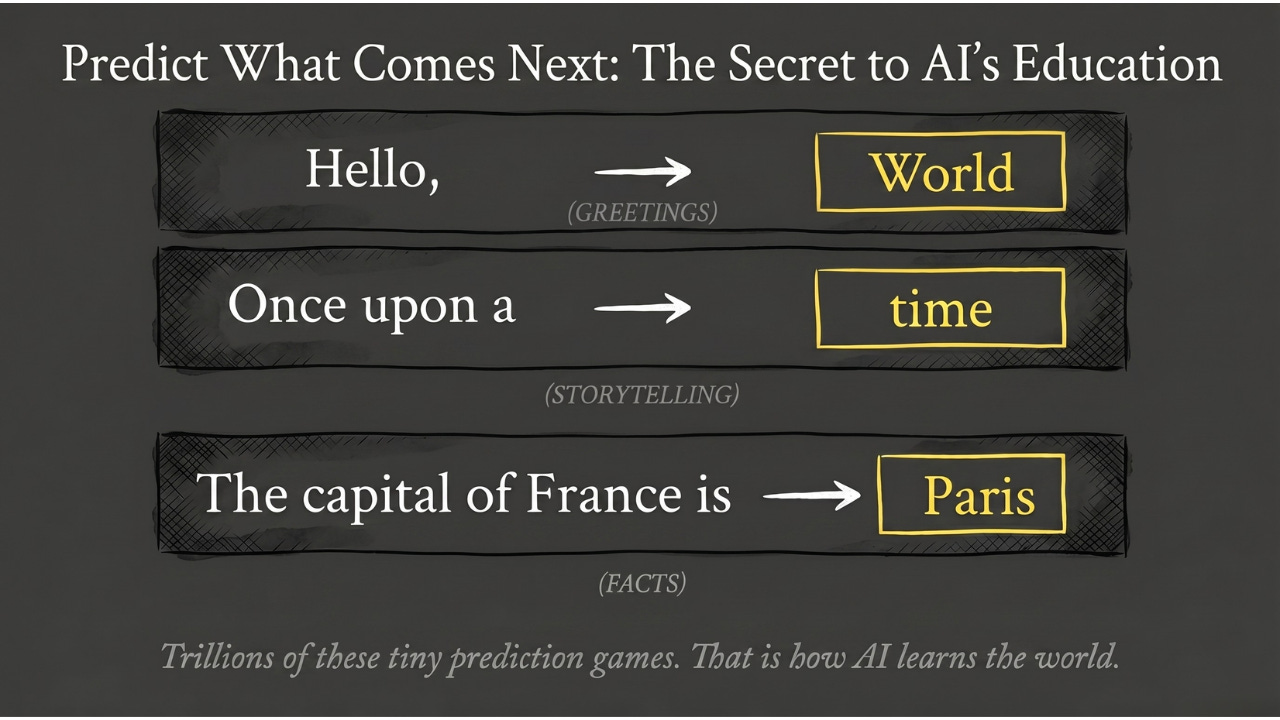
The Solution: Predict What Comes Next
Pre-training flips the problem on its head. Instead of teaching the AI a specific job immediately, we let it loose on a massive amount of data — the internet, books, papers, code — with one beautifully simple goal: predict what comes next.
The AI reads billions of sentences and tries to guess the next word over and over. After “Hello,” the next word is often “World” or “There.” After “Once upon a,” it is almost always “time.” Through trillions of these tiny prediction games, the model gradually picks up grammar, language patterns, factual knowledge, and slang — the broad shape of how the world is described in text.
The beautiful part: nobody has to label anything. The next word in the sentence is itself the answer.
It learns the general features of the world first.
-
In images: it learns what edges, circles, and shapes look like before it learns what a “face” is.
-
In text: it learns how language works before it learns how to write a poem about your dog.
The whole philosophy comes from a simple idea in transfer learning: don’t reinvent the wheel. If a model already exists that understands the basics, build on top of that knowledge instead of starting from zero.
The Analogy: The Medical Student
To understand pre-training versus what comes after it, think of a medical student.
-
Pre-training (Medical School): The student spends years reading textbooks and learning anatomy, biology, and chemistry. They aren’t treating patients yet. They are just building a massive foundation of general knowledge. They know a little bit about everything.
-
Specialty Training (Residency): Now that student goes to a hospital to specialize, maybe in cardiology, maybe in surgery. They take all that general knowledge and focus it on one specific task.

A pre-trained model like GPT-5, Claude, or Gemini is the medical school graduate. It has read the library. It is smart and broad, but it hasn’t specialized in your company’s data, your customer’s tone, or your industry’s jargon yet. That comes later.
Why is This a Game Changer?
Before pre-training became the standard, if you wanted to build an AI to translate languages, you needed a massive labeled dataset of English-to-French sentences. If you didn’t have that data, you were stuck. Every new task meant starting from zero.
With pre-training:
-
You need less data later. Because the model already knows English, you only need to show it a small number of examples of what you specifically want it to do for it to catch on.
-
You skip the hardest part. A pre-trained foundation already exists. You just point it at the specific job you care about.
A note on scale, because this matters for understanding why pre-training is such a big deal in 2026: back when this technique first took off around 2018–2020, pre-training a small language model was a days-or-weeks project on a modest cluster. Today’s frontier models — GPT-5, Claude, Gemini — take months to pre-train, run on tens of thousands of GPUs, and cost hundreds of millions of dollars in compute alone. Pre-training has gotten bigger, not smaller, as AI has scaled.
The Takeaway

Pre-training is the heavy lifting. It is the process of creating a Foundation Model — a knowledgeable generalist that can later be pointed at almost any task.
-
It is the bridge between a blank computer brain and one that has read the library.
-
It is the difference between teaching a baby to write a novel (impossible) and asking a college graduate to write a novel (possible).
-
It is the layer underneath every modern AI you use — ChatGPT, Claude, Gemini, Copilot — built long before you ever typed a single prompt.
One honest caveat for 2026: pre-training is the foundation, but it is not the whole story anymore. Modern AI also goes through additional specialty training on top of pre-training, and that is where today’s models learn to be helpful, careful, and reasoning-capable. We’ll dig into that in the upcoming articles.
When you use ChatGPT or Claude, you are talking to a model that has already finished its general education. It has read the library. Now it is ready to work for you.
Coming Up
You now know what pre-training is — the general-education phase where AI learns how the world is described in text. But how does the AI actually do the learning? What does the day-to-day classroom look like? Next, we’ll walk through the study, practice, and test loop — the actual mechanics of how a blank-slate model goes from random guesses to meaningful answers.
AI for Common Folks – Making AI understandable, one concept at a time.
Leave a Reply