
How AI learns is not magic, not science fiction, and not a mystery reserved for PhD researchers. It’s a loop: predict, measure how wrong you were, adjust, and try again. The same way you learned to cook.

Hey Common Folks!
If you’ve ever heard someone say “we trained an AI model” and wondered what that actually means, this one’s for you. Not the buzzword version. Not the textbook version. The real version, explained the way you’d explain it to a friend over chai.
The Problem: Some Things You Can’t Explain
Normally, when a programmer wants a computer to do something, they write exact instructions. Step 1, do this. Step 2, do that. Like a recipe with precise measurements.
“Take the list of numbers. Compare the first two. If the first is bigger, swap them. Move to the next pair. Repeat.”
This works great for things where humans know the exact steps. Sorting numbers. Calculating taxes. Sending an email.
But what about recognizing a dog in a photo?
Try it right now. Look at a photo of a dog and explain, step by step, exactly how you know it’s a dog. Not “it has fur and four legs,” because so does a cat, a bear, and a wolf. What EXACTLY are the steps your brain takes?
You can’t write them down. Nobody can. Your brain does it instantly, but the process is invisible even to you.
So if you can’t explain it to yourself, how do you explain it to a computer?
The Breakthrough: Stop Explaining. Start Showing.
Back in 1949, an IBM researcher named Arthur Samuel had this exact problem. And his idea was simple but radical:
What if we stop writing instructions for the computer? What if we just show it thousands of examples and let it figure out the pattern on its own?
Like a grandma teaching you to cook. She didn’t hand you a formula. She let you try, told you how it turned out, and let you adjust.
That’s machine learning. That’s the whole idea.
The Chai Analogy: How the Learning Actually Works
Imagine you’re learning to make chai. There are things you can control: how much sugar, how much ginger, how long you boil the milk, how many tea leaves. Let’s call these your settings.
On your first try, you just guess. Two spoons of sugar, a small piece of ginger, boil for 3 minutes, one spoon of tea leaves. You taste it. Too sweet, no kick, kind of watery.
Now here’s the important part. You don’t throw everything out and start with a completely random guess. You think: “Too sweet means I need less sugar. No kick means more ginger. Watery means I should boil longer or add more tea leaves.” You adjust your settings based on what went wrong.
You try again. Better. Still not great. You adjust again. And again. After 30 cups, you’re making chai that people actually want to drink.
What just happened?
-
You had settings you could adjust (sugar, ginger, boil time, tea leaves)
-
You had a way to score the result (tasting the chai)
-
You used that score to figure out which settings to change and in which direction (too sweet means LESS sugar, not more)
-
You repeated this process until the score was good
That’s the entire structure of machine learning. Every single AI system in the world follows this pattern.
Now Replace Yourself With a Computer
In machine learning, the “settings” are called weights. They’re just numbers. Thousands of them, sometimes billions. Each one is like one of your chai settings: a small dial that slightly changes the final output.
The “thing being cooked” is called a model. It’s a program that takes an input (like a photo) and produces an output (like “dog” or “cat”). But the output depends entirely on where the weights are set. Same model, different weights, completely different results. Just like same kitchen, same ingredients, but different amounts of sugar and ginger give you completely different chai.
The “tasting” is called a loss function. It’s just a score that measures how wrong the model was. Show it a photo of a dog and it says “cat”? High score (very wrong). It says “dog”? Low score (good). The computer doesn’t “understand” dogs. It just has a number that tells it how far off it was.
The “figuring out which settings to change” is the clever part. Remember how you knew “too sweet” means reduce sugar, not increase it? The computer does something similar. It looks at the score and mathematically traces back through the model to figure out: which weights contributed to the wrong answer, and in which direction should I nudge each one to make the score a little better? This isn’t magic. It’s math. If turning a weight up made things worse, turn it down a little. If turning it down made things better, keep going that direction.
The “trying again” is called training. The computer looks at an example, makes a prediction, checks the score, adjusts the weights, and repeats. Not 30 times like your chai experiment. Millions of times. Across thousands of examples. Each time the weights get a little better. The score gets a little lower. The predictions get a little more accurate.
And Then Something Remarkable Happens
After enough rounds of tasting and adjusting, the model gets good. Show it a photo of a dog it has never seen before, and it says “dog.” Show it a cat, it says “cat.” Not because anyone wrote rules for what a dog looks like. Because the model adjusted its own settings, millions of times, based on millions of examples, until the patterns clicked into place.
Just like you can now walk into any kitchen, with any ingredients, and make decent chai without thinking about it. You don’t follow a recipe anymore. You have a feel for it. The model has its version of that feel: billions of finely tuned weights.
And here’s the part that matters. Once training is done, you lock in the weights. Now the model is just a program. Photo goes in, answer comes out. From the outside, it looks like any other software. The difference is nobody wrote the instructions. The machine found them by practicing.
Your grandma’s teaching method, at scale.
Want to See the Actual Math? Let’s Walk Through It.
Forget images and dogs for a minute. Let’s say you’re trying to predict how much chai your office will drink based on how many people show up.
You’ve noticed a pattern over the past few days:
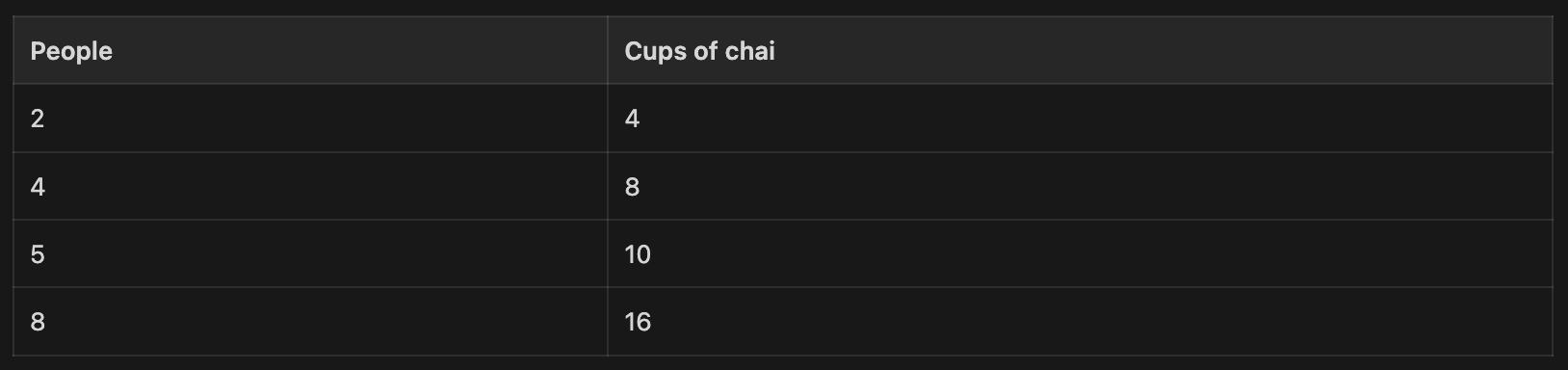
You can probably see the pattern already: it’s roughly 2 cups per person. But pretend you don’t know that. Pretend you’re a computer that has to figure it out by guessing and adjusting.
Start with a random guess.
The model is the simplest possible formula:
prediction = weight x people
One input (people), one weight (some number we haven’t figured out yet), one output (predicted cups).
Let’s start with weight = 0.5. That’s our first guess.
Round 1: Predict and check.
2 people showed up, they drank 4 cups.
prediction = 0.5 x 2 = 1
We predicted 1 cup. The real answer was 4. Way off.
error = prediction – actual = 1 – 4 = -3
Negative means we predicted too low. The size (3) tells us how far off.
Now, which direction do we nudge the weight?
Our formula was: prediction = weight x people. We predicted too low. The input (people = 2) is fixed. The only thing we can change is the weight. If we make it bigger, the prediction goes up. We need it to go up. So the weight needs to increase.
But by how much? Machine learning uses a formula:
new weight = old weight – learning rate x error x input
The “learning rate” is a small number that controls how big each step is. Let’s use 0.1. Too big and you overshoot. Too small and you take forever.
new weight = 0.5 – 0.1 x (-3) x 2 = 0.5 + 0.6 = 1.1
The error was negative (too low), so the math automatically pushed the weight UP. No if-statement needed. The math handles the direction for us.
Round 2:
prediction = 1.1 x 2 = 2.2
error = 2.2 – 4 = -1.8 (still too low, but closer)
new weight = 1.1 – 0.1 x (-1.8) x 2 = 1.1 + 0.36 = 1.46
Round 3:
prediction = 1.46 x 2 = 2.92
error = 2.92 – 4 = -1.08
new weight = 1.46 + 0.216 = 1.676
Let’s skip ahead and see the pattern:
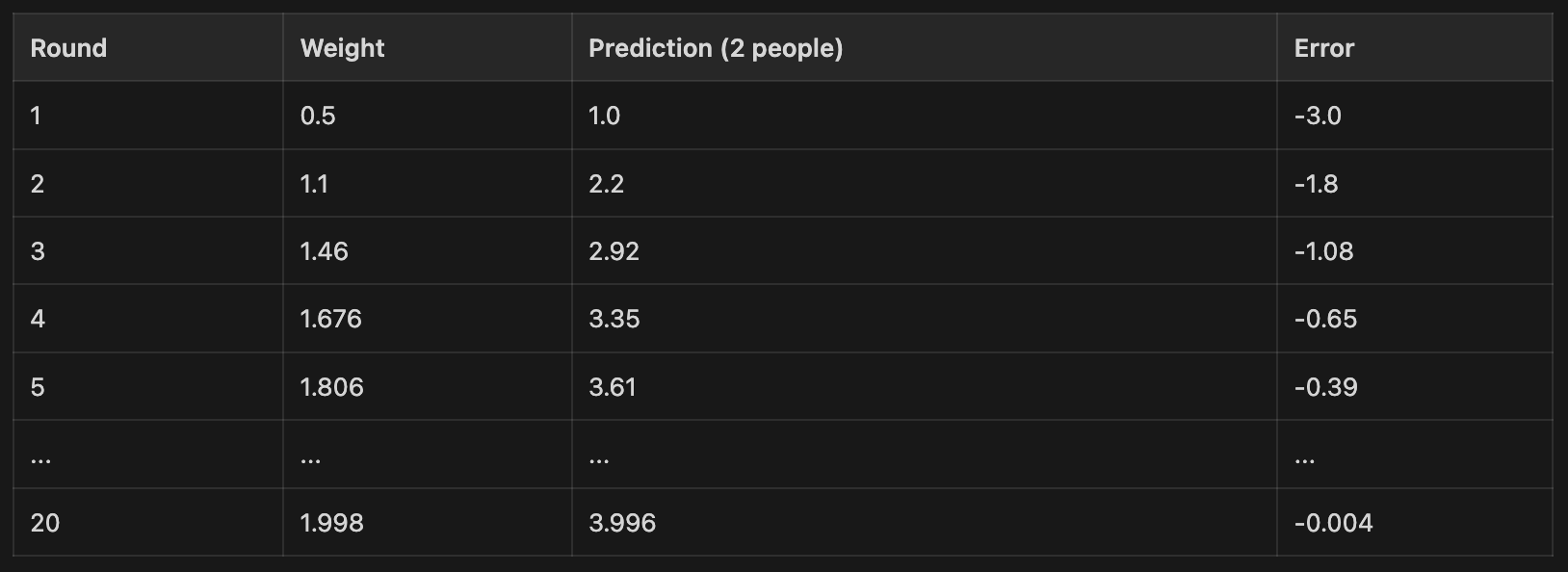
The weight crawls toward 2.0. The prediction crawls toward 4.0. The error shrinks toward 0.
Nobody told the computer the answer was 2 cups per person. It started at 0.5 and found its way there by repeatedly predicting, checking the error, and nudging the weight in the right direction.
Connect it back to the chai analogy:
-
The weight (started at 0.5) is the chai setting. The sugar, the ginger, the dial you’re adjusting.
-
The prediction is the chai you made this round.
-
The error is you tasting it and knowing how far off it is.
-
The update rule is you thinking “too weak, needs more.” Except here it’s a formula, not a feeling.
-
The learning rate (0.1) controls how cautious you are. Small sips and small adjustments, not dumping the whole spice jar in at once.
This was one weight. One input. One simple formula.
A real AI model? Same exact process. Same loop. But instead of one weight, it has billions. Instead of “people to chai cups,” it’s “pixels to dog or cat.” Instead of multiplying one number, it passes data through layers of weights, each one getting nudged a tiny bit after every example.
The math gets bigger. The idea doesn’t change.
Predict. Check the error. Adjust the weights. Repeat.
A Note for Common Folks
This article is an attempt to explain how AI learns at the simplest level possible. We skipped a lot of nuance on purpose. Real AI systems are more complex, but the core loop you just read about is genuinely how they all work, from the simplest model to ChatGPT.
One important thing to understand: computers don’t see images, hear sounds, or read text the way you do. A computer only understands numbers. Specifically, everything inside a computer is 0s and 1s.
So how does AI handle different types of input?
Images are stored as grids of numbers. Each pixel has a number for how red it is, how green, and how blue. A 1000×1000 photo is just 3 million numbers. That’s what the model actually “sees.” Not a dog. Not colors. Just a grid of numbers.
Sound is stored as a sequence of numbers representing the wave of air pressure hitting a microphone, thousands of times per second. Your favorite song is just a very long list of numbers.
Text is converted into numbers through a process called tokenization. Each word or piece of a word gets assigned a number. “The cat sat” might become [458, 2093, 7721]. That’s what the model actually reads.
So when we say “a model takes an input and produces an output,” what we really mean is: numbers go in, math happens (weights multiply and add), and numbers come out. The model then maps those output numbers back to something humans understand, like the word “dog” or the next word in a sentence.
That’s why the same learning loop works for everything. Images, audio, text, medical scans, stock prices, language translation. It’s all numbers. And the model is doing the same thing every time: adjusting its weights to get better at turning one set of numbers into another.
If you understood the chai analogy, you understand how AI learns. The rest is just scale.
The Takeaway
Machine learning is not a computer “thinking.” It’s a computer adjusting its own settings, over and over, based on how wrong its guesses are, until the guesses get good enough. The same way you learned to cook, ride a bike, or throw a ball. Try, check, adjust, repeat.
The difference is speed and scale. You made 30 cups of chai. The computer makes 30 million guesses. You adjusted 4 settings. The computer adjusts 30 billion. But the process? Identical.
AI for Common Folks — Making AI understandable, one concept at a time.
Leave a Reply