GPT stands for Generative Pre-trained Transformer — a family of AI models built by OpenAI that powers ChatGPT and defined the modern era of AI.
AI for Common Folks
Apr 2026
Hey Common Folks!
In our last article on Foundation Models, we talked about the general-purpose brains that power modern AI — the Swiss Army Knives trained to do everything from writing code to drafting emails. Before that, we explored Generative AI, the broad category of AI that creates new content.
Now let’s zoom in on the most famous Foundation Model family of them all: GPT.
You see it everywhere. GPT-4, GPT-5, ChatGPT. But what do those three letters actually stand for? Is it a robot? A company? A magic spell?
Here’s the real story: GPT is not just an acronym. It is three separate breakthroughs in AI that had never been combined at massive scale. OpenAI put them together, and that combination is why modern AI works.
Let’s unpack each one.
What is GPT?
GPT stands for Generative Pre-trained Transformer.
It is a specific type of Large Language Model (LLM) developed by OpenAI. If AI is the broad industry, GPT is a specific product line, like the “iPhone” of AI models.
But here is the part nobody tells you: each of those three words (Generative, Pre-trained, Transformer) represents a problem that AI researchers had been stuck on for decades. GPT is the name for what happened when all three got solved at the same time.
Before GPT: Three Problems AI Couldn’t Crack
To understand why GPT matters, you have to understand what AI looked like before it existed.
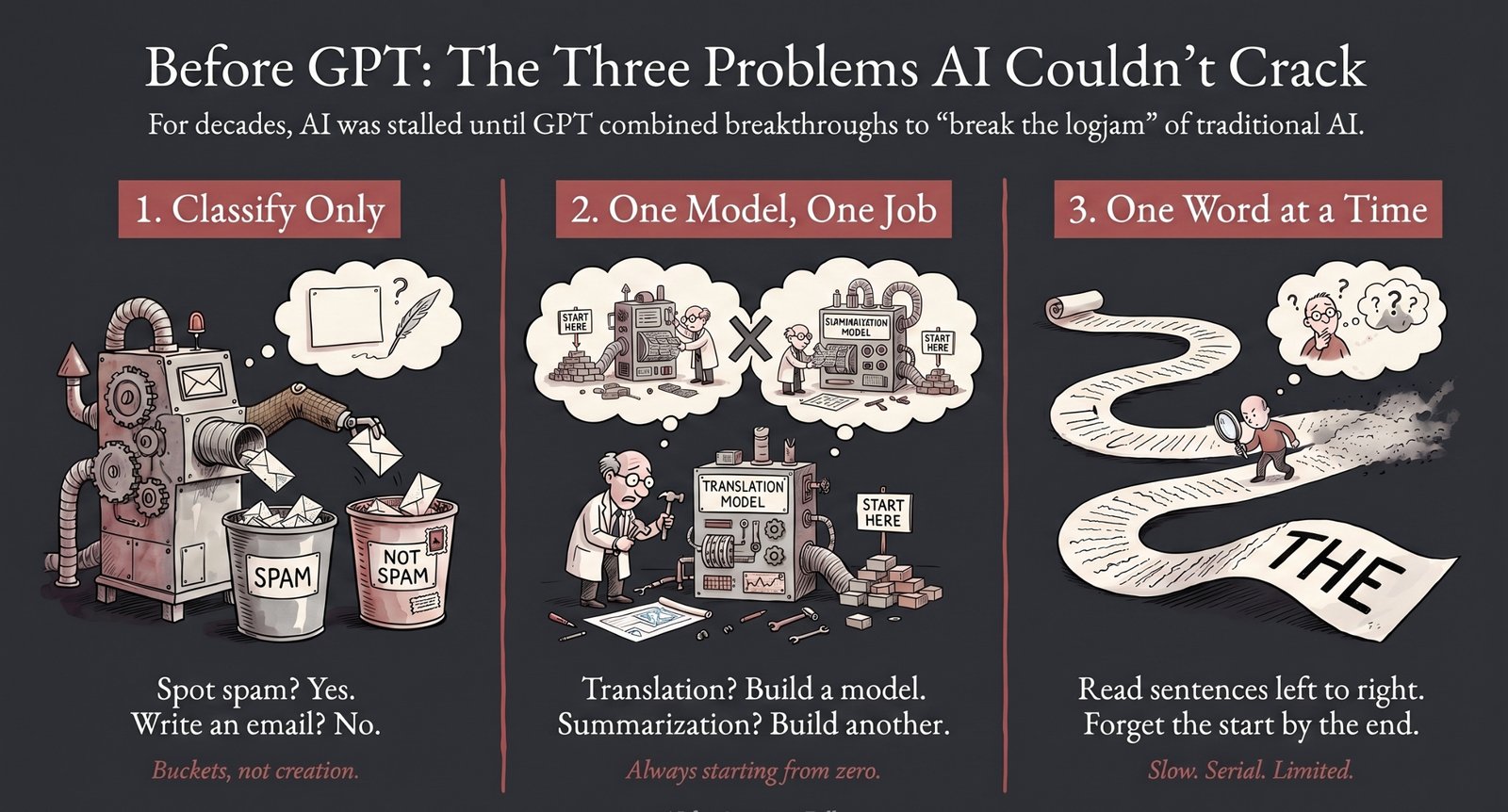
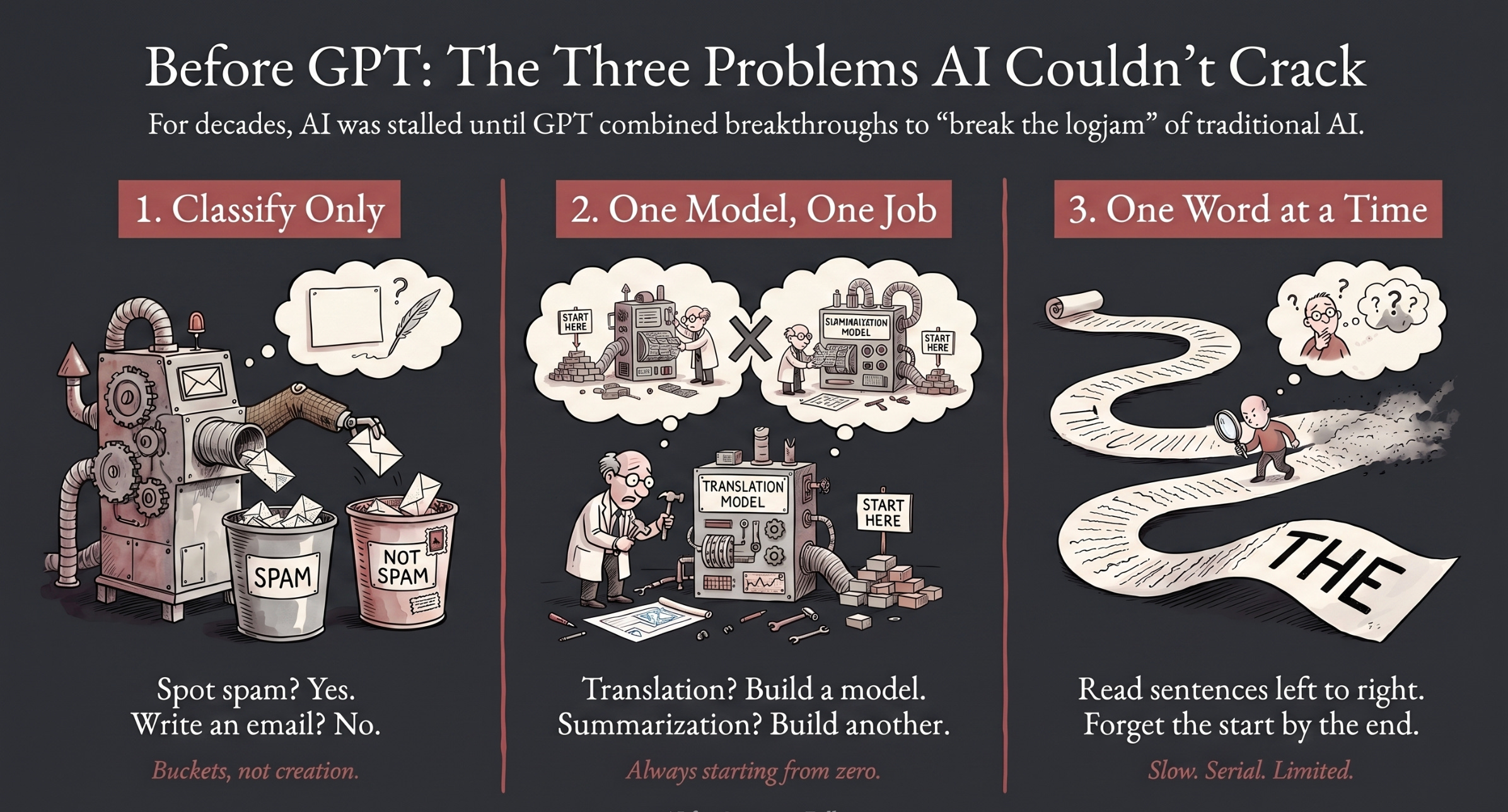
For most of AI’s history (roughly the 1950s through the 2010s), researchers were stuck on three problems simultaneously:
-
AI could classify, but it couldn’t create. It could tell you if an email was spam, but it couldn’t write an email.
-
AI had to be trained from scratch for every task. Want translation? Build a translation model. Want summarization? Build a summarization model. One model, one job, always starting from zero.
-
AI could only read one word at a time. The dominant technology of the day (called RNNs and LSTMs) processed text sequentially, like reading a book strictly left to right. It was slow, and by the end of a long sentence, it had often forgotten the beginning.
Every single letter in “GPT” was an answer to one of these problems. Let’s take them one by one.
1. G is for Generative: The Shift from “Classify” to “Create”
This is the easy part to say, but the hardest to appreciate.
What it means: GPT can create new content. Essays, code, poetry, emails. It generates output that didn’t exist before.
Why it’s a big deal: For decades, AI was a world of “yes/no” answers. Is this spam? Is this a cat or a dog? Does this customer churn? These are classification tasks. AI looks at something and puts it in a bucket.
Creating something new from scratch (a paragraph, a story, a working function of code) was considered nearly impossible. Language is infinite. There are more possible sentences than atoms in the universe. How would an AI pick a good one?
The Generative approach said: don’t pick the “right” sentence. Generate it word by word, always predicting the most likely next word given what came before. Do that billions of times, and coherent writing emerges.
That sounds simple. It is also the shift that took AI from “recognizing patterns in data” to “creating patterns that look human.”
2. P is for Pre-trained: The Free Labels Trick
This one is the real genius, and most explanations skip it.
What it means: Before GPT is ever asked to do anything useful, it has already read a massive amount of text. Books, Wikipedia, websites, articles, code. That’s the “pre” in pre-trained.
Why it’s a big deal: Traditional AI needed labeled data. To teach AI to spot spam, humans had to label millions of emails as “spam” or “not spam.” To teach it to tell cats from dogs, humans had to label millions of photos. Labeled data is expensive, slow, and limited.
Pre-training flipped the entire problem on its head with one insight:
If the task is “predict the next word,” the internet is already labeled. The label is just the next word.
Read “The cat sat on the ___” and the correct answer is whatever word came next in the original sentence. No humans needed. The data labels itself. And the internet has trillions of words.
Suddenly, AI had unlimited training data. GPT-3 was trained on roughly 570 GB of filtered text, pulled from an even larger 45 TB of raw internet data. Later models like GPT-4 and GPT-5 used dramatically more. That scale would have been unimaginable with human-labeled data.
Think of Pre-training as a student reading every book in the library to learn general knowledge. Later, this student can be Fine-tuned (specialized training for a specific job) to become a doctor, a coder, or a chatbot. But the broad education comes first, and it comes from the text itself.
3. T is for Transformer: Seeing All the Words at Once
What it means: The Transformer is a specific type of Neural Network architecture introduced by Google researchers in 2017, in a paper famously titled “Attention Is All You Need.”
Why it’s a big deal: Before Transformers, AI read sentences one word at a time, sequentially. This was slow, and the model often forgot the beginning of a long sentence by the time it reached the end. It also meant you couldn’t spread the work across thousands of chips in parallel, which put a hard ceiling on how big these models could get.
Transformers introduced two superpowers:
-
Parallel Processing: They look at all the words in a sentence simultaneously, rather than one by one. This makes them dramatically faster and, critically, scalable to billions of parameters. Without Transformers, no amount of compute could have produced GPT-3 or GPT-4.
-
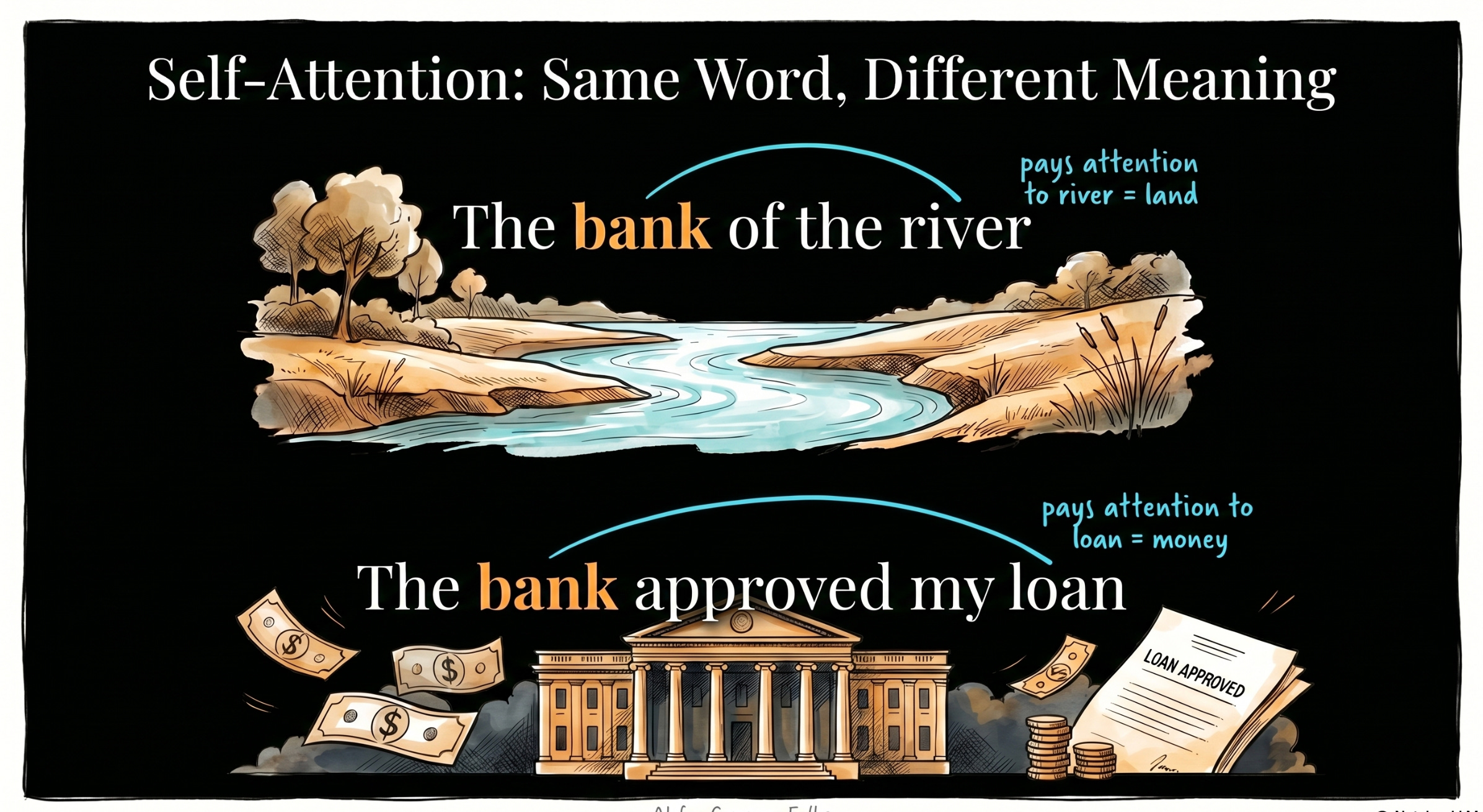
Self-Attention: They figure out which words in a sentence relate to each other. In “The bank of the river,” the Transformer pays attention to “river” to know that “bank” means land. In “The bank approved my loan,” it pays attention to “loan” to know bank means the financial kind. Same word, different meaning, figured out from context.
Self-attention is what gave AI something that looks like understanding context. It is the single architectural idea that made modern AI possible.
Why the Combination Changed Everything
Here’s the thing nobody emphasizes enough: each of these three ideas existed on its own before GPT.
-
Researchers had built generative models before.
-
Unsupervised pre-training had been explored in smaller forms.
-
The Transformer paper was published by Google, not OpenAI.
What OpenAI did was combine all three at massive scale. GPT-1 in 2018 showed the recipe could work. GPT-2 in 2019 showed it could write coherently. GPT-3 in 2020 was the moment the world saw what happens when you push this recipe to billions of parameters: the model started doing things it was never explicitly trained to do. Reasoning. Translation. Summarization. Rudimentary code generation. Researchers call these emergent abilities. Capabilities that appear, seemingly out of nowhere, once the model gets big enough.
ChatGPT in late 2022 was when the public caught on.
So when someone says “GPT changed AI,” they are not being dramatic. The specific combination of Generative + Pre-trained + Transformer at scale is the recipe that broke a decades-long logjam.
GPT vs. ChatGPT
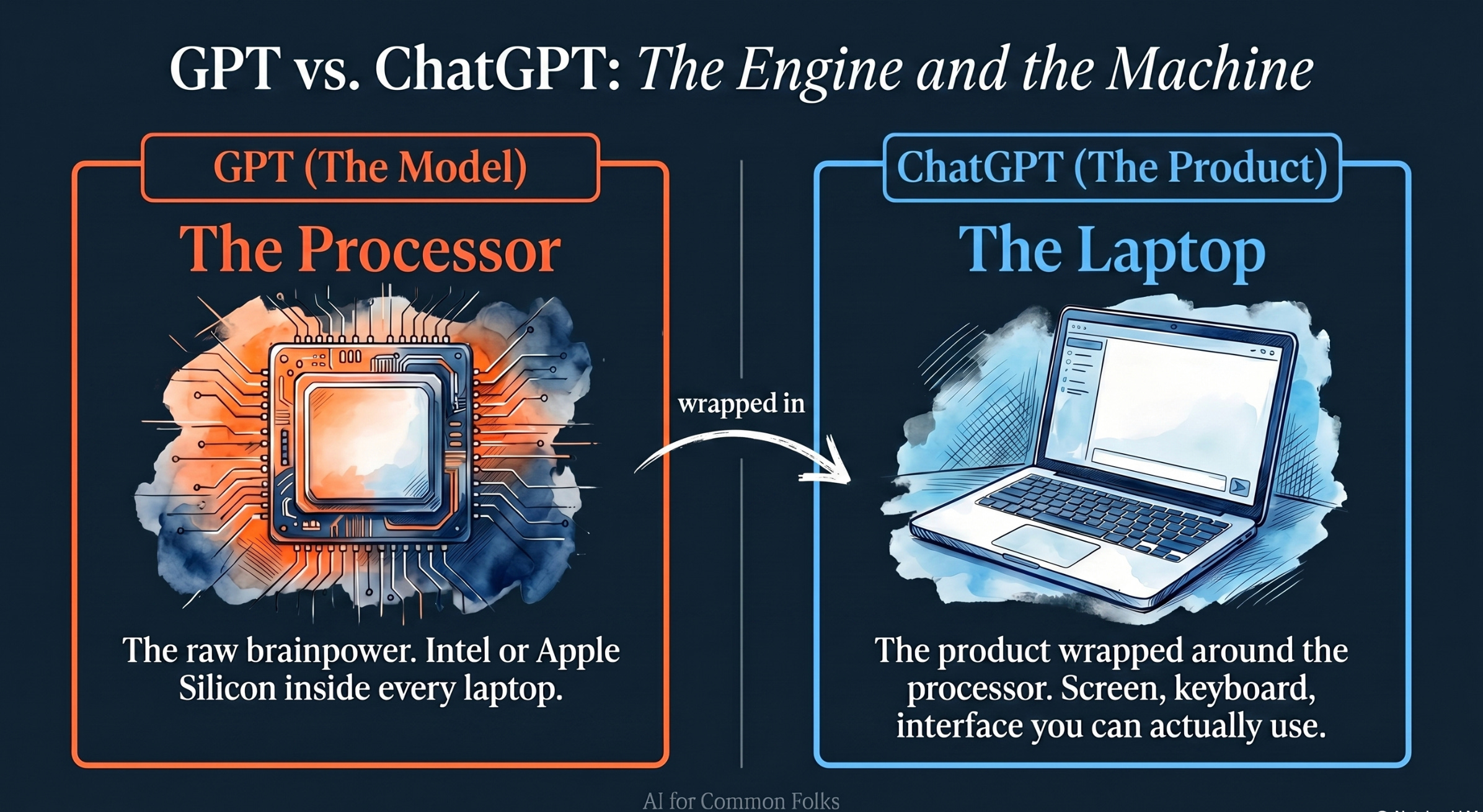
Are they the same thing? No.
Here is the best analogy to understand the difference:
Think of a Laptop.
-
GPT is the Processor (like Intel or Apple Silicon): It is the raw brainpower and technology that does the thinking.
-
ChatGPT is the Laptop (like a MacBook or Dell XPS): It is the product wrapped around that processor with a screen and keyboard (an interface) that allows you to interact with it easily.
GPT is the model; ChatGPT is the application built using the GPT model.
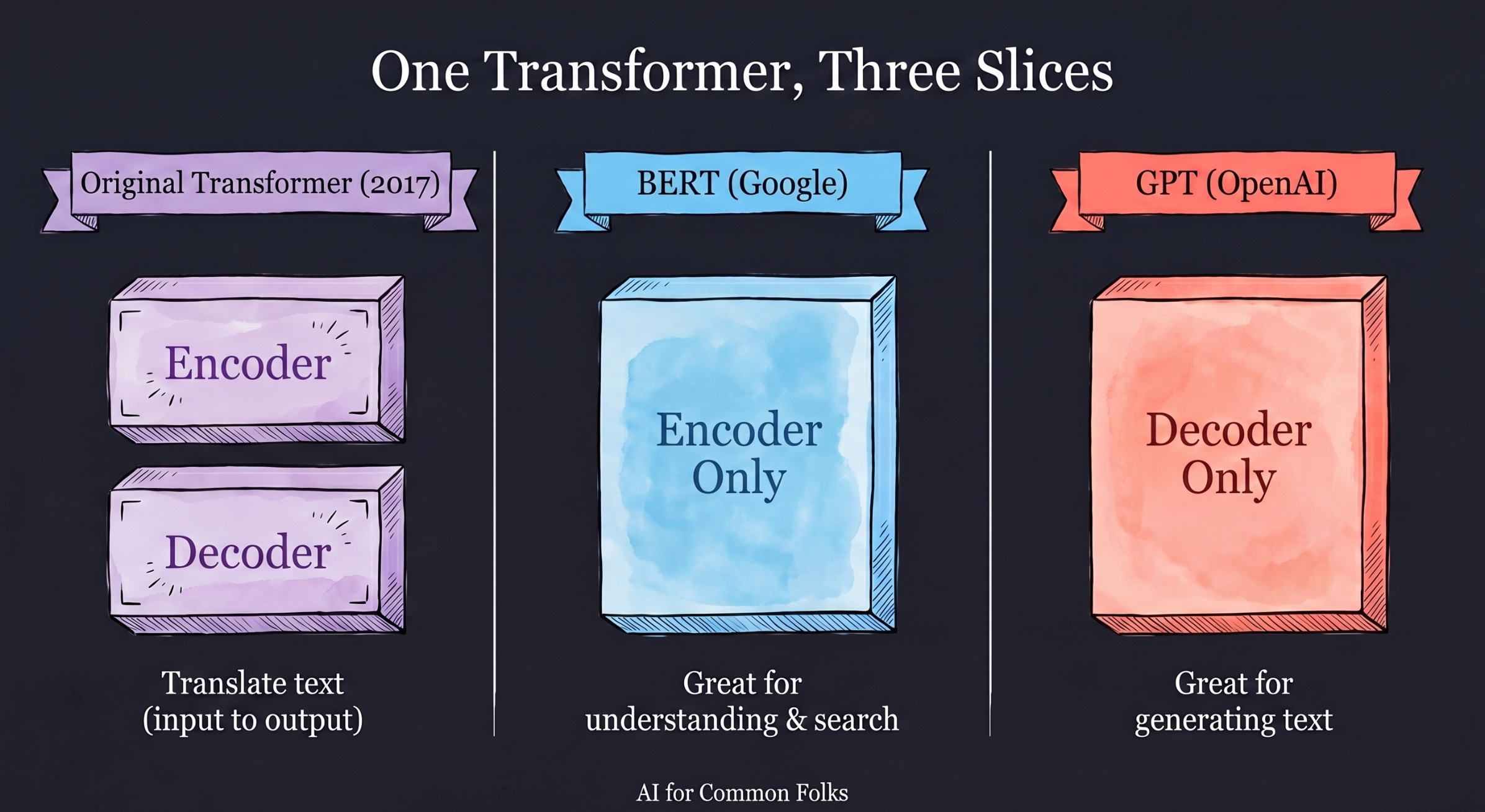
The “Decoder” Secret
If you want to sound extra smart, know this: the Transformer architecture originally came with two parts, an Encoder (to understand input) and a Decoder (to generate output).
GPT models are actually Decoder-only models. They dropped the Encoder entirely. They are specialists in generating text: predict the next token, then the next, then the next, until they have built a whole sentence.
Different AI systems use different slices of the Transformer architecture. Google’s original BERT was Encoder-only (great for understanding and search). GPT is Decoder-only (great for generating). That single design choice is a big part of why GPT models feel so fluent when they write.
The Takeaway
You didn’t just learn what an acronym stands for. You learned the three ingredients that made modern AI possible:
-
Generative: AI stopped classifying and started creating.
-
Pre-trained: The internet itself became the training data, no humans needed to label it.
-
Transformer: AI stopped reading one word at a time and started seeing the whole picture at once.
Each of these had been tried separately. Combining them at scale, between 2018 and 2020, is what OpenAI did. And it is the reason “GPT” became shorthand for modern AI.
The next time someone says “we’re in the GPT era,” you’ll know they don’t mean an acronym. They mean a recipe.
Coming Up
You now know what GPT stands for. But here is a subtle point we glossed over: GPT is just one example of a broader category called Large Language Models (LLMs). Claude, Gemini, Llama, and DeepSeek are LLMs too. So what exactly is an LLM, and why is it the engine behind every chatbot you use? In our next article, we’ll break down the engine behind ChatGPT, Claude, and Gemini and show you why LLMs are the defining technology of this decade.
AI for Common Folks – Making AI understandable, one concept at a time.
Leave a Reply