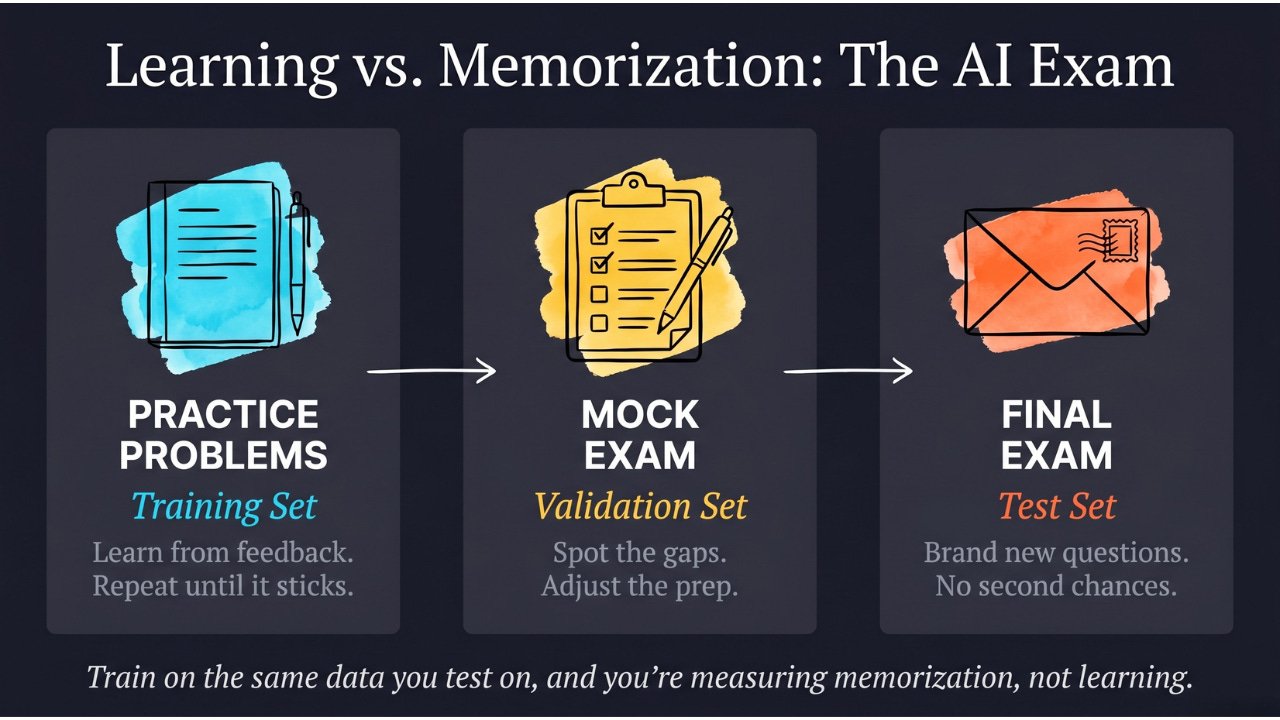
Training, validation, and test sets are the three separate groups of data every AI model needs to learn properly, tune itself, and be fairly evaluated — like practice problems, a mock exam, and the actual final exam, each playing a completely different role.

Hey Common Folks!
Last edition, we walked through pre-training — the general-education phase where an AI model reads the internet and slowly learns how the world is described in text. We ended with a promise: come back and show you what the day-to-day classroom actually looks like. This is that edition.
Because pre-training raises a question that sits right underneath it: how does a data scientist know whether the model has genuinely learned something, or just memorized the examples it was shown?
The answer comes down to a simple but crucial idea: you need to test a model on data it has never seen before. And to do that correctly, you have to split your data into three very specific groups from the start.
That’s what training, validation, and test sets are all about.
The Exam Analogy
Think back to how you prepared for an important exam in school.
Your textbook came with practice problems at the end of each chapter. You worked through them, checked your answers, and kept reviewing the material you got wrong. These are your training set — examples you learn from, with feedback.
Then your teacher handed out a mock exam. You hadn’t seen these specific questions before, but you used them to figure out where you still had gaps. Based on how you did, you went back and studied those weak areas. These are your validation set — a checkpoint to help you tune your preparation.
Finally: the real exam. Brand new questions, no second chances, no adjustments afterward. This is the only true measure of whether you actually learned. This is your test set.
Here’s the critical rule: you cannot use the same data for all three purposes. If you train on the same examples you test on, you’re not measuring learning — you’re measuring memorization. It’s like scoring a student on the exact practice problems they studied. A perfect score tells you nothing.
The Three Sets Explained
Training Set
This is the largest portion of your data — usually around 70-80%. The model learns from this data. It sees thousands or millions of examples, makes predictions, gets corrected, and adjusts its parameters. This is where all the actual learning happens.
The model sees the training data over and over again across multiple training runs. It’s allowed to learn from its mistakes here.
Validation Set
This is typically 10-15% of your data. The model never trains on this data — it only uses it to check its progress.
During training, you periodically pause and run the model on the validation set. If the model’s accuracy on training data is climbing but its accuracy on the validation set is flat or dropping, you’re watching overfitting happen in real time. The model is memorizing training examples instead of learning generalizable patterns.
The validation set also helps you make decisions: Should you train for more epochs? Should you adjust the learning rate? Should you use a simpler model? Every tuning decision gets made based on how the model performs here — not on the training set.
Test Set
This is the smallest portion — maybe 10-15% — and it gets used exactly once: at the very end, after all training and tuning is complete.
The test set is your honest final grade. The model has never seen these examples. You haven’t made any decisions based on them. This is the only clean measurement of how the model will perform on truly new data.
If you use the test set during tuning — making adjustments based on test performance — you’ve contaminated it. You’ve effectively turned it into a validation set, and now you have no honest evaluation left.

What Happens When You Get This Wrong
Skipping or contaminating the test set is more common than you’d think, and the consequences can be serious.
In the late 2010s and early 2020s, AI medical-imaging papers regularly landed in major journals reporting accuracy figures in the 90s — sometimes claiming they could spot tumors, predict COVID, or flag heart disease nearly perfectly. A 2021 review published in Nature Machine Intelligence looked at over 2,000 such papers on COVID detection alone and found that not a single one was clinically useful. The most common reason? Data leakage. The “test set” had quietly seen the same patients, the same scanners, or the same preprocessing as the training set. The exam was rigged.
When hospitals tried to deploy these tools on truly new patients, accuracy collapsed.
This isn’t just a technical problem. When AI is making recommendations about someone’s cancer diagnosis, loan application, or parole hearing, the gap between “performed well in testing” and “performs well on real people” has real consequences.
By 2026, the response has started to bite. The FDA now expects AI medical-device submissions to demonstrate performance on prospective test data — patients enrolled after the model was already locked in — because retrospective test sets had proven too easy to contaminate, even by accident. A properly held-out test set is the closest thing we have to a clean, honest audit before deployment, and regulators have stopped trusting anything weaker.
An Important Twist: Cross-Validation

Sometimes your dataset is small enough that you can’t afford to lock away 15% as a test set — you need every example to train on.
In those cases, data scientists use a technique called cross-validation. Instead of one fixed split, you divide the data into five or ten equal “folds.” You train on nine of them and validate on the tenth. Then you rotate — train on a different nine, validate on the remaining one. Repeat until every fold has been the validation set exactly once.
This gives you a more reliable estimate of how the model will perform on new data without sacrificing training examples. It’s slower, but it’s smart when data is scarce.
Where You See This in Practice
Every responsible AI system uses this three-set approach, even if the terminology differs.
Google testing a new search ranking algorithm trains on historical search data, validates on recent data to tune the approach, and evaluates on a final held-out period before pushing anything to production.
Netflix’s recommendation models train on older viewing history, validate on more recent history to catch drift and tune parameters, and measure final performance on the most recent week of data they haven’t touched.
Even the foundation models behind ChatGPT, Claude, and Gemini get evaluated on held-out benchmarks the model has never seen during pre-training — though, as we’ll see in a future edition, even those held-out exams are getting harder to keep clean as models scale.
The principle is always the same: learn on one thing, tune on another, and only trust what you measure on something completely separate from both.
The Takeaway
The training set teaches the model. The validation set helps you tune it. The test set honestly evaluates it.
Confuse these roles — or skip any of them — and you lose the ability to know whether your AI actually works.

This is why, when you hear “AI achieved 95% accuracy,” the right question isn’t “how high is the number?” It’s “what data was it tested on, and was that data truly held out?” The number only means something if the exam was fair.
Every AI tool you trust — from medical imaging to fraud detection to the spam filter keeping your inbox clean — depends on data scientists getting this split right before it ever reaches you.
Coming Up
We’ve now seen the clean version of how AI learns — labeled examples, a tidy split, an honest final exam. But that whole picture assumes someone already labeled the data for you. In the real world, most data shows up messy and unlabeled. Nobody has sat down to tag every tweet, every photo, or every customer record.
So what happens when you take the answer key away? Can AI still learn anything useful from a pile of raw, unsorted data? Next edition: how AI learns without a teacher.
Was this helpful? Did you know this was how AI gets tested? Reply and let us know what you want us to explain next.
AI for Common Folks — Making AI understandable, one concept at a time.
Leave a Reply