Fine-tuning is the process of taking a pre-trained AI model that already has general knowledge and training it further on a smaller, specialized dataset to make it an expert at one specific task — like sending a brilliant generalist back to school for a residency.
Hey Common Folks!
The last few editions have all been about how an AI gets its broad education. We covered pre-training — the heavy lifting where a model reads the internet and learns how the world is described in text. Then we covered the train, validate, test split — the honest classroom that tells us whether the model actually learned anything. Both phases describe how a generalist AI gets built.
But here’s the catch: a pre-trained model is exactly that — a generalist. It knows a little bit about everything, but it isn’t an expert in your specific business. It knows what a “receipt” is, but it doesn’t know how your company processes expenses.
To turn the generalist into a specialist, we use a process called fine-tuning.
What is Fine-Tuning?
It’s the machine learning equivalent of “don’t reinvent the wheel.” Instead of building a new brain from scratch, you take an existing brain that already understands the world and teach it one specific skill on top.
The pre-trained model is the wheel. Fine-tuning is the car you build around it.
The Analogy: The Medical Student vs. The Cardiologist
In the pre-training article we left the medical student standing at the end of medical school — a knowledgeable generalist who has read the textbooks but hasn’t specialized. Now we pick up where that left off.
-
Pre-training (Medical School): The student spends years learning general anatomy, biology, and chemistry. They know how the human body works in general. They are smart, but you wouldn’t want them performing heart surgery on you yet. This is your Foundation Model — GPT, Claude, Gemini, before any specialization.
-
Fine-tuning (Residency): Now that general doctor goes through specialized training to become a cardiologist. They stop reading general biology textbooks and focus entirely on the heart. Crucially, they use their previous general knowledge to pick up the specialty much faster than someone starting from zero.
Fine-tuning is what turns the general doctor into the cardiologist. It takes the broad capabilities the model already has and focuses them on a single, specific job.

Why Do We Need It? The “Generalist” Problem
You might ask: if the model has read the whole internet, isn’t it already smart enough?
Not exactly. There are two gaps a generalist can’t close on its own:
-
The Data Gap: The model might know what a dog is, but if you want it to distinguish between a “phone” and a “tablet” the way your product catalog defines them (categories that weren’t emphasized in its original training), it will struggle.
-
The Tone Gap: A generic model sounds like a generic robot. If you want it to sound like your customer support agent (polite, empathetic, using your company’s specific lingo), you need to teach it that specific style.
Fine-tuning is the bridge between general knowledge and specific application.

How Does It Work?
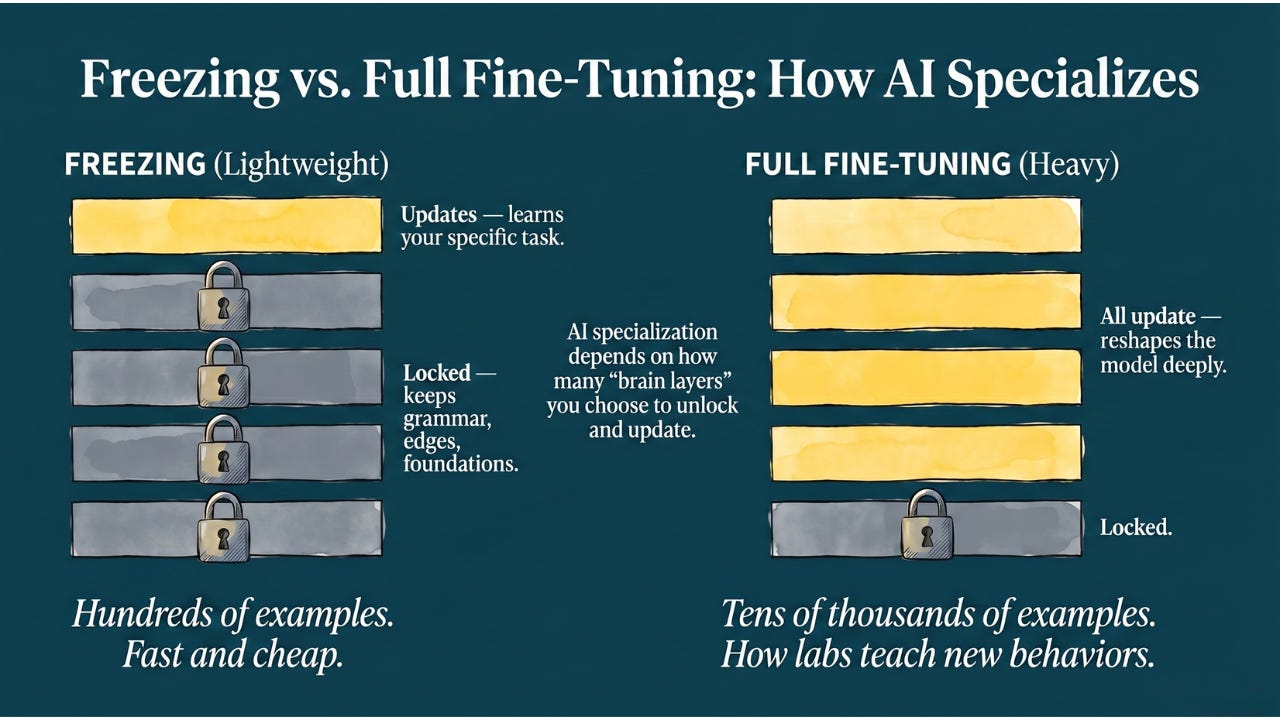
When we fine-tune, we don’t want the model to forget everything it learned during pre-training. We don’t want the doctor to forget how to read blood pressure while learning heart surgery. There are two common ways to pull this off, both versions of a broader idea called transfer learning.
The lightweight approach: freezing. We lock the parts of the model that understand foundational things (grammar, what an “edge” looks like in an image) and only let it update its “last layers,” the parts responsible for making the final decision on your specific task. Show it a few hundred examples of your company’s legal contracts and, because it already understands English from pre-training, it picks up the pattern of your contracts very quickly.
The heavier approach: full fine-tuning. We unfreeze most of the model and let it update widely, but with a much smaller learning rate so it doesn’t lose what it already knows. This needs more data, often tens of thousands of examples, but it can reshape the model far more deeply. It’s how labs teach a model entirely new behaviors, like how to follow instructions or how to sound like a helpful assistant.
Either way, you don’t need the millions of examples that pre-training required. You’re not rebuilding the brain, you’re just pointing an existing intelligence in a new direction.
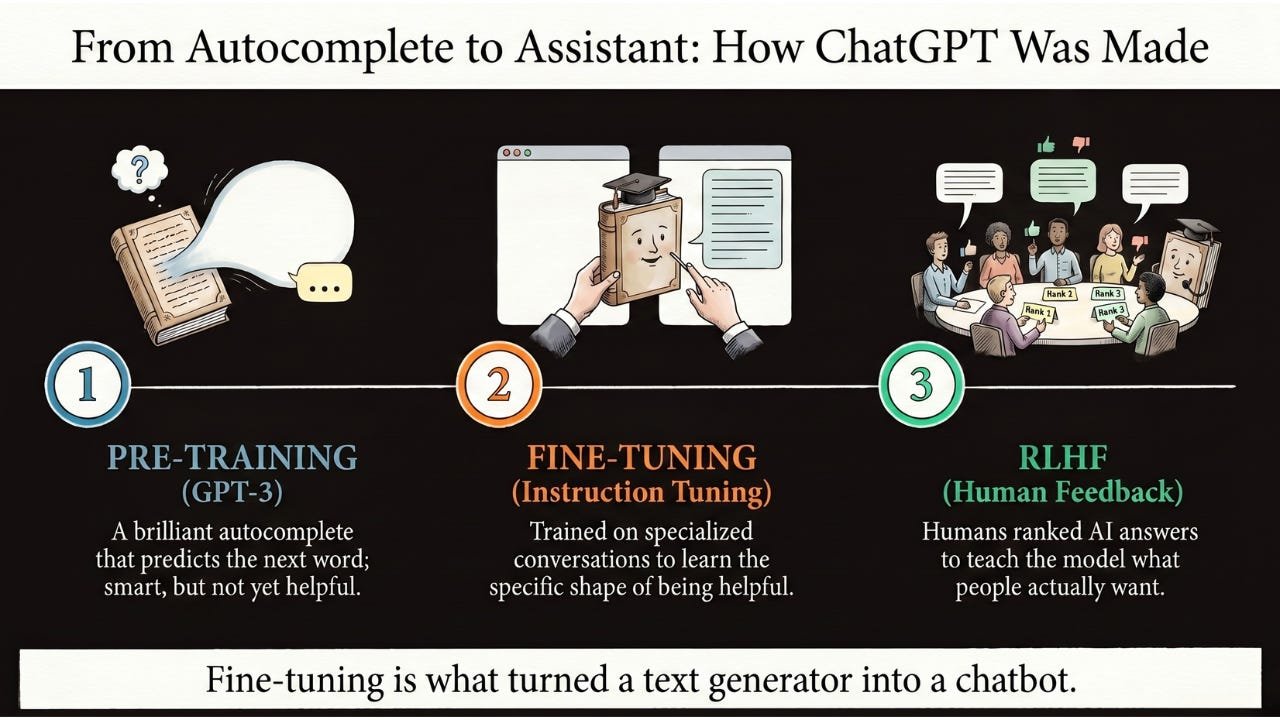
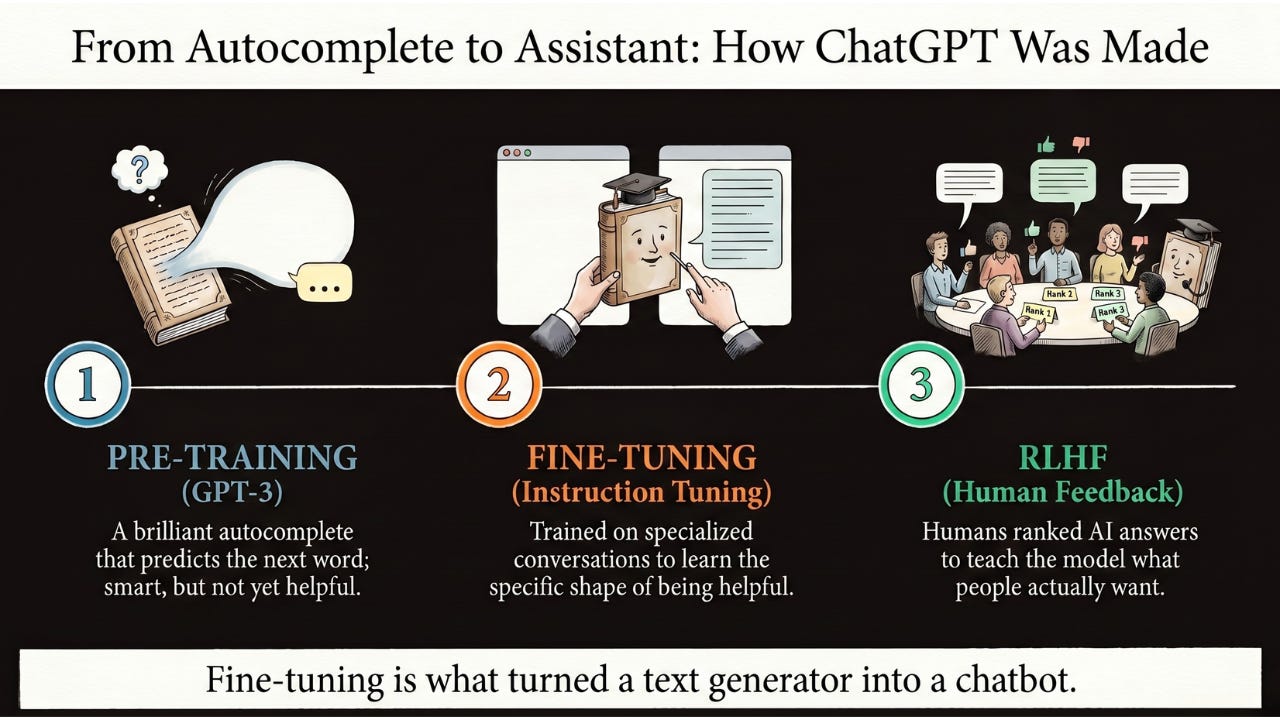
Real-World Magic: How ChatGPT Was Made
The clearest example of fine-tuning in action is ChatGPT itself.
-
Pre-training (GPT-3): OpenAI trained a massive model to predict the next word in a sequence. It was smart, but it wasn’t helpful. If you typed a question, it might keep going with more questions instead of answering. It was a brilliant autocomplete, not an assistant.
-
Fine-tuning (Instruction Tuning): They then fine-tuned it on a dataset of conversations. Humans demonstrated: when a user asks X, the assistant should respond with Y. The model learned the shape of being helpful.
-
Refinement (RLHF): They then used a related technique called Reinforcement Learning from Human Feedback, where humans ranked pairs of AI answers (”this one is better than that one”) and the model learned to prefer the kinds of answers humans actually wanted. This is the step that taught the model to be helpful, harmless, and conversational.
Without fine-tuning, GPT-3 was just a text generator. Fine-tuning is what turned it into a chatbot.
And the same recipe is still in play today. Every new version of ChatGPT, Claude, or Gemini follows the same playbook: pre-train a massive generalist, then fine-tune it to be helpful, safe, and conversational. The base models keep getting bigger and smarter; the underlying principle doesn’t change.
Is Building a Custom GPT the Same as Fine-Tuning?
Short answer: no, but a lot of people use the words interchangeably.
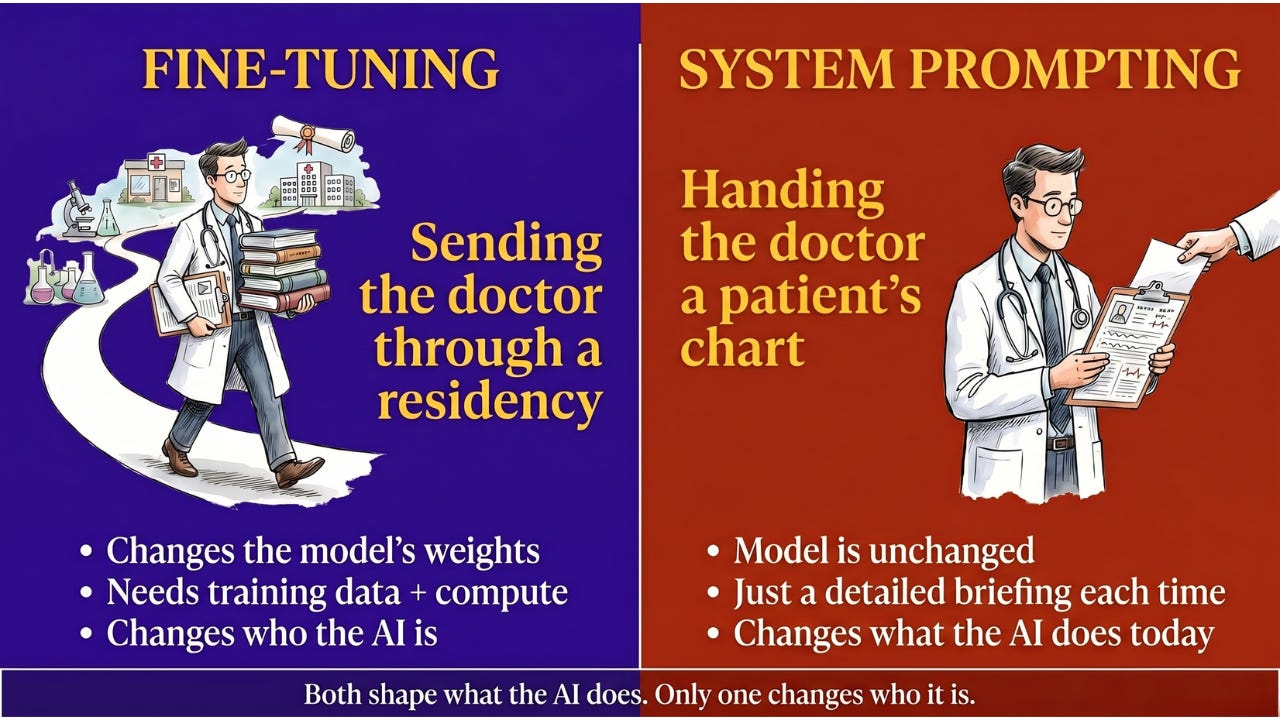
When you create a Custom GPT in ChatGPT, or set up a Claude Project, or write a long system prompt for your chatbot, you’re doing something different from what we’ve described above. You’re not training the model. You’re not changing its weights, its memory of how the world works, or any of the numbers inside its brain. The model itself is exactly the same as everyone else’s.
What you’re actually doing is giving it a really detailed briefing every time it starts a conversation. It’s the difference between sending a doctor through a residency (real fine-tuning) and handing that same doctor a patient’s chart right before the appointment (prompting). Both shape what they do. Only one changes who they are.
This kind of customization is called system prompting, and when you also upload reference files for the AI to consult, it’s called retrieval. It’s much cheaper and faster than real fine-tuning. You don’t need any training data, any compute, or any ML team. And for most everyday use cases (a customer-support bot for your store, a writing assistant for your team, a tutor for your kids), prompting is more than enough.
Real fine-tuning is what you reach for when prompting hits its limit. When you need the model to learn a pattern it just won’t pick up from instructions, or when you have thousands of examples of what good output looks like and want the model to truly internalize the style. For everything else, a good system prompt is usually faster, cheaper, and easier to iterate on.
In casual conversation, people often say “I fine-tuned my GPT” when they really just wrote a clever system prompt. The slip is small, but worth knowing: one of these changes the AI itself, the other just changes its instructions for the day.
The Takeaway
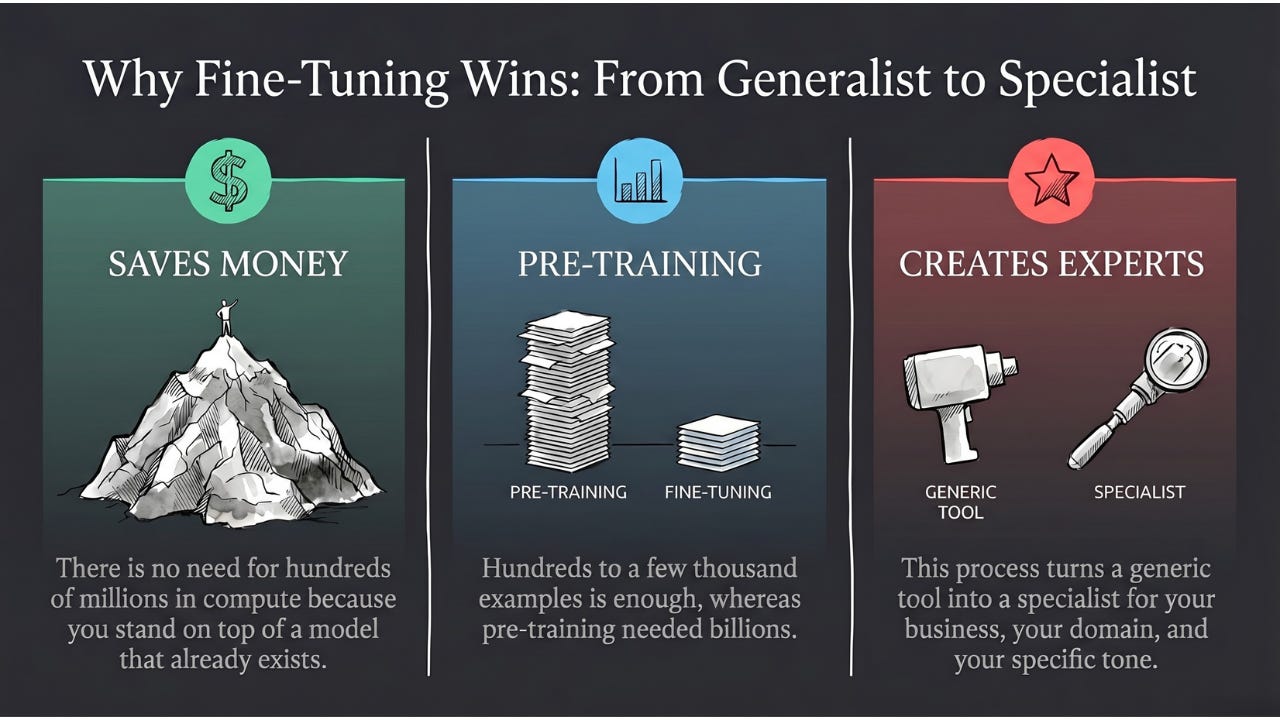
Fine-tuning is how we customize AI for the real world.
-
It saves money. You don’t need hundreds of millions of dollars in compute to train a model from scratch — you stand on top of one that already exists.
-
It saves data. You can get strong results with hundreds or a few thousand examples, instead of the billions pre-training requires.
-
It creates experts. It turns a generic tool into a specialized solution for your business, your domain, your tone.
Every AI product you use that feels weirdly tuned to a specific job (a customer support bot that sounds like the company, a coding assistant that knows your team’s style, a medical AI that flags conditions a generalist would miss) has been fine-tuned somewhere underneath.
Coming Up
Fine-tuning lets you specialize a generalist model with way less data than training from scratch. But what if you barely have any data, like 500 X-rays for a rare disease instead of 500,000? You can’t train from scratch and you don’t have enough to fine-tune properly either.
Next edition: how AI learns from tiny datasets by cheating fairly — a technique called data augmentation.
Was this helpful? Did the medical-school analogy click? Reply and let us know what you want us to explain next.
AI for Common Folks — Making AI understandable, one concept at a time.
Leave a Reply