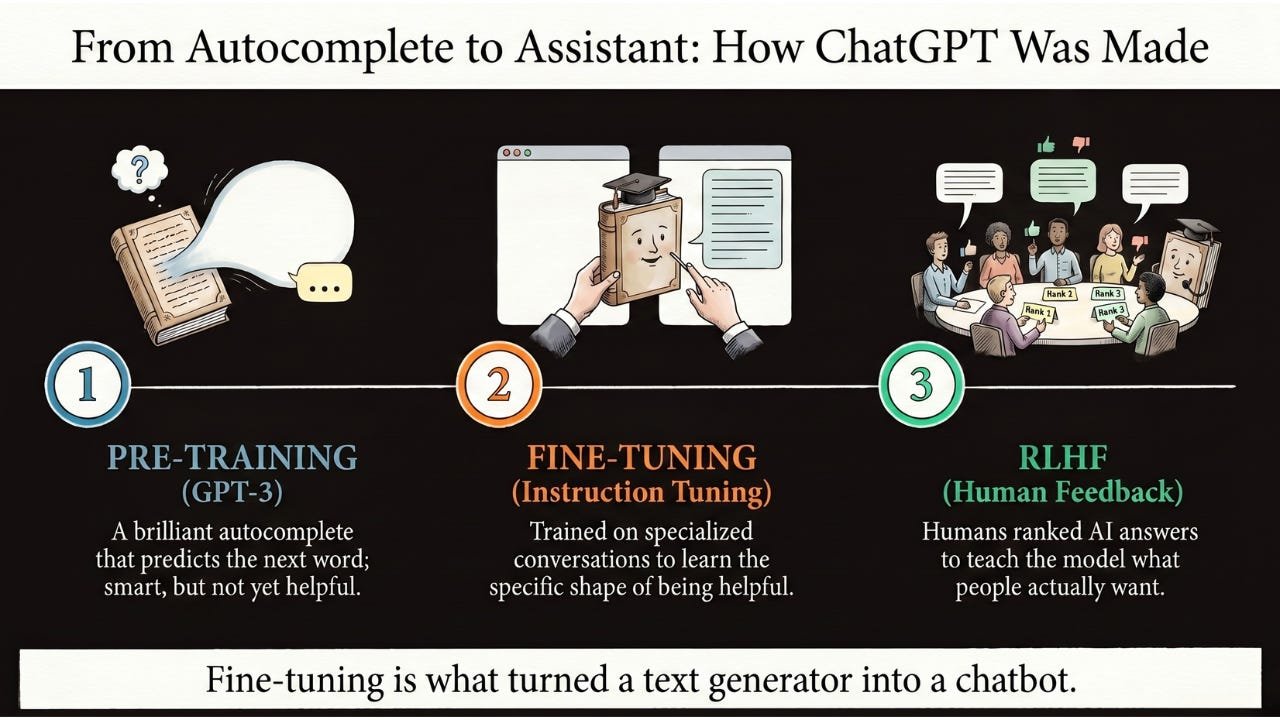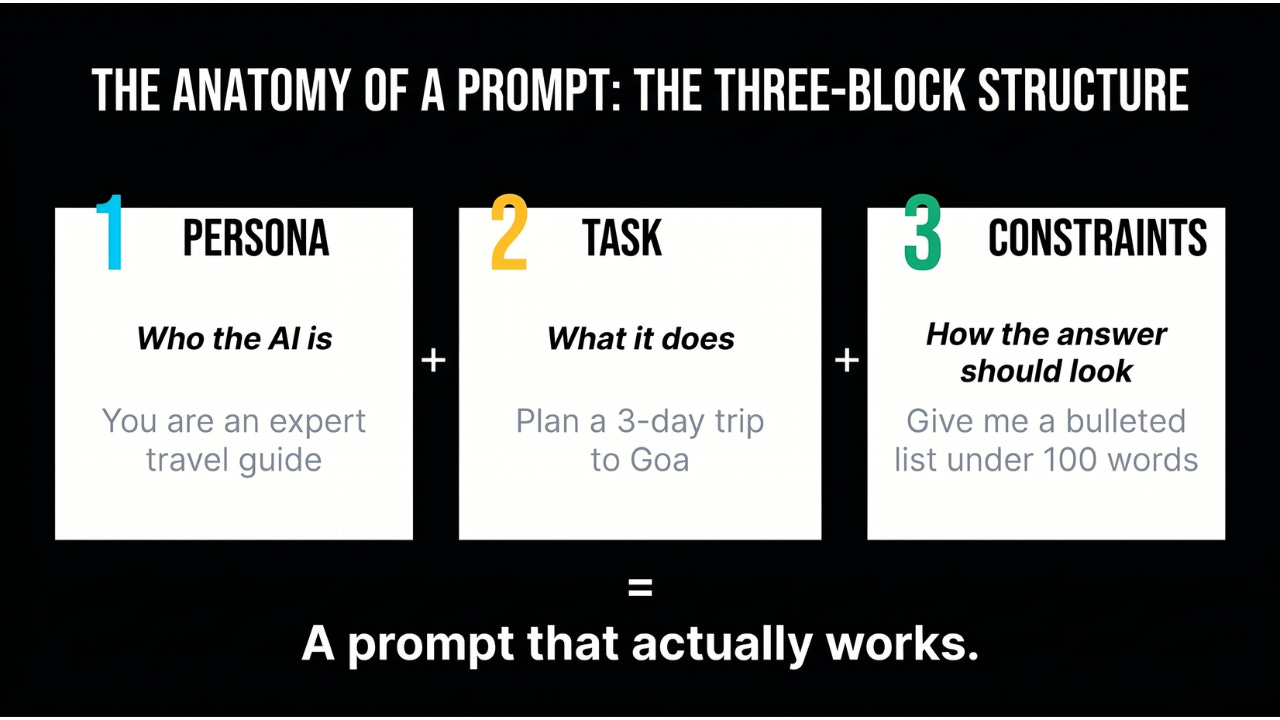
Data augmentation is the technique of artificially expanding an AI’s training dataset by creating modified versions of existing examples, helping models learn more robust patterns from less data and resist the temptation to memorize specific examples.
Hey Common Folks!
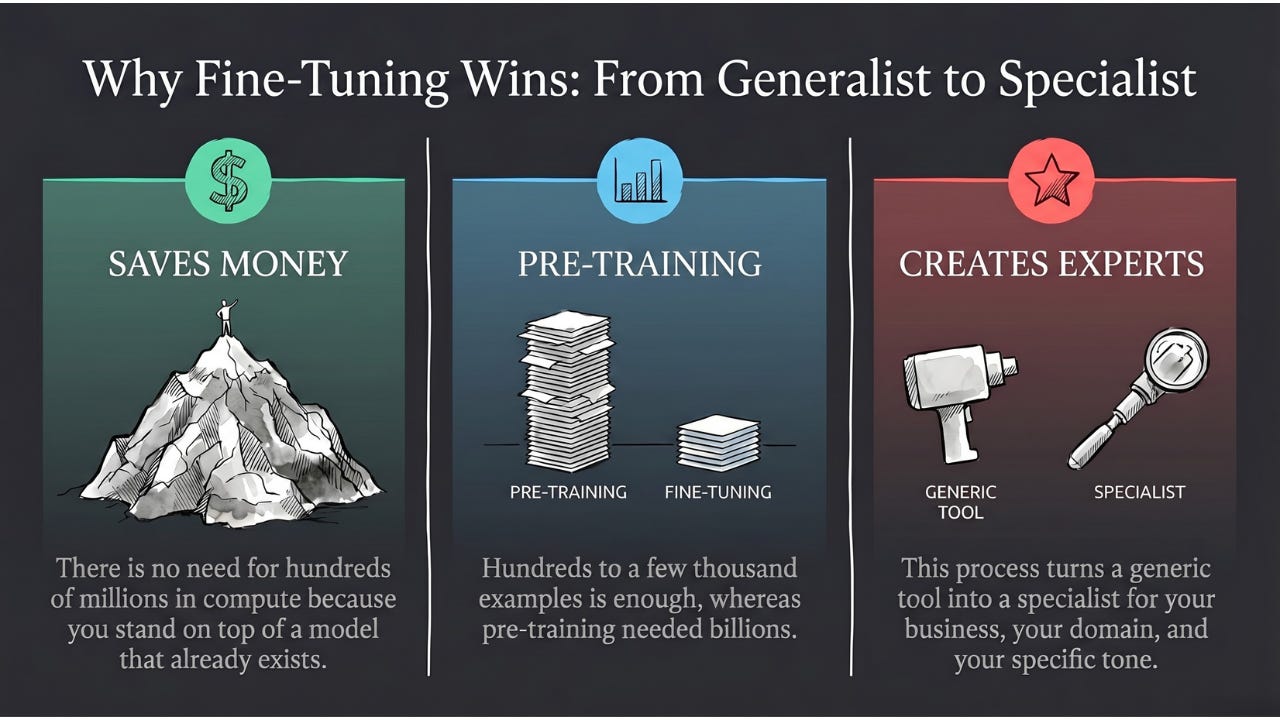
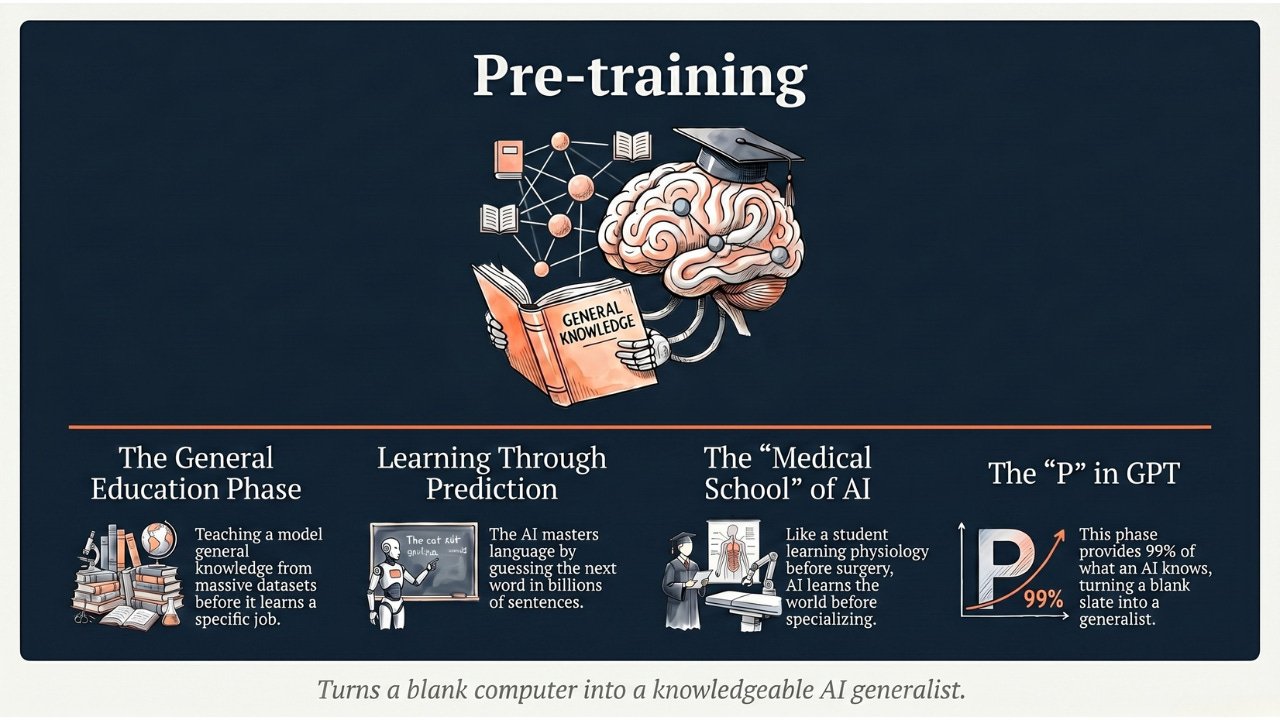
Last edition, we saw how fine-tuning can specialize a generalist model with just a few hundred examples. But that still assumes you have a few hundred. What if you don’t? What if you have 50 X-rays of a rare disease, 200 photos of a specific defect on your factory line, or only a few thousand sentences of a language that barely has any written text?
Today’s edition is about one of the most elegant ideas in the field — the technique that lets AI learn more from less. It’s the reason medical AI can work with 500 X-rays instead of 500,000, why your phone’s face recognition works in unusual lighting, and why self-driving cars can handle road conditions they’ve never literally seen before.
The Music Student Analogy
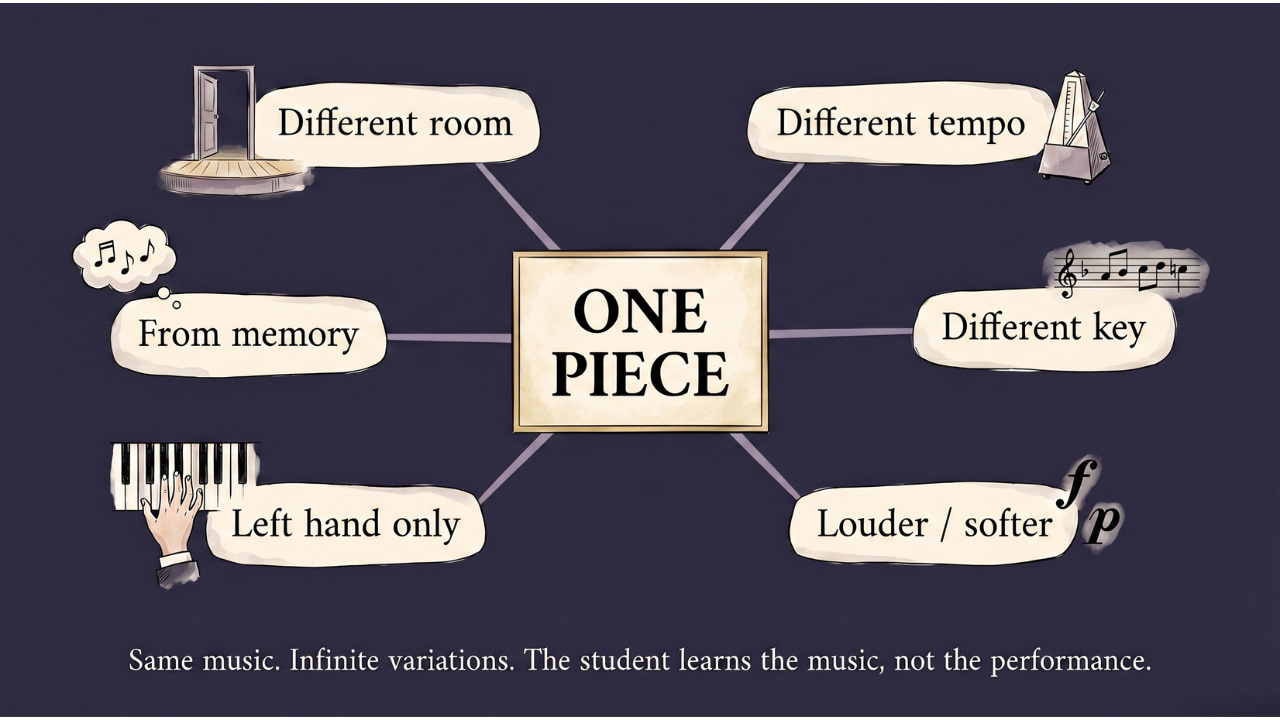
Imagine a music student learning to play a piece on the piano.
The teacher could have them play it exactly as written, at the same tempo, every day until they have it memorized. They’d get very good at that exact performance. But show them the same piece in a different key, or ask them to play it slightly faster, or have them perform in a different room with different acoustics, and they might struggle. They memorized the piece — not the music.
A better teacher has the student play the same piece at different tempos. In different keys. With different dynamics, louder, softer, more staccato. Forwards. Sometimes just the left hand, sometimes just the right. From memory, from the sheet, from hearing it.
Same piece. Infinite variations. The result: the student understands the music deeply enough to adapt to any performance context.
Data augmentation is this second approach, applied to AI training.
What Data Augmentation Actually Does
Instead of training on the same set of examples repeatedly, data augmentation creates new variations of those examples, modified versions that show the model the same underlying concept from different angles.
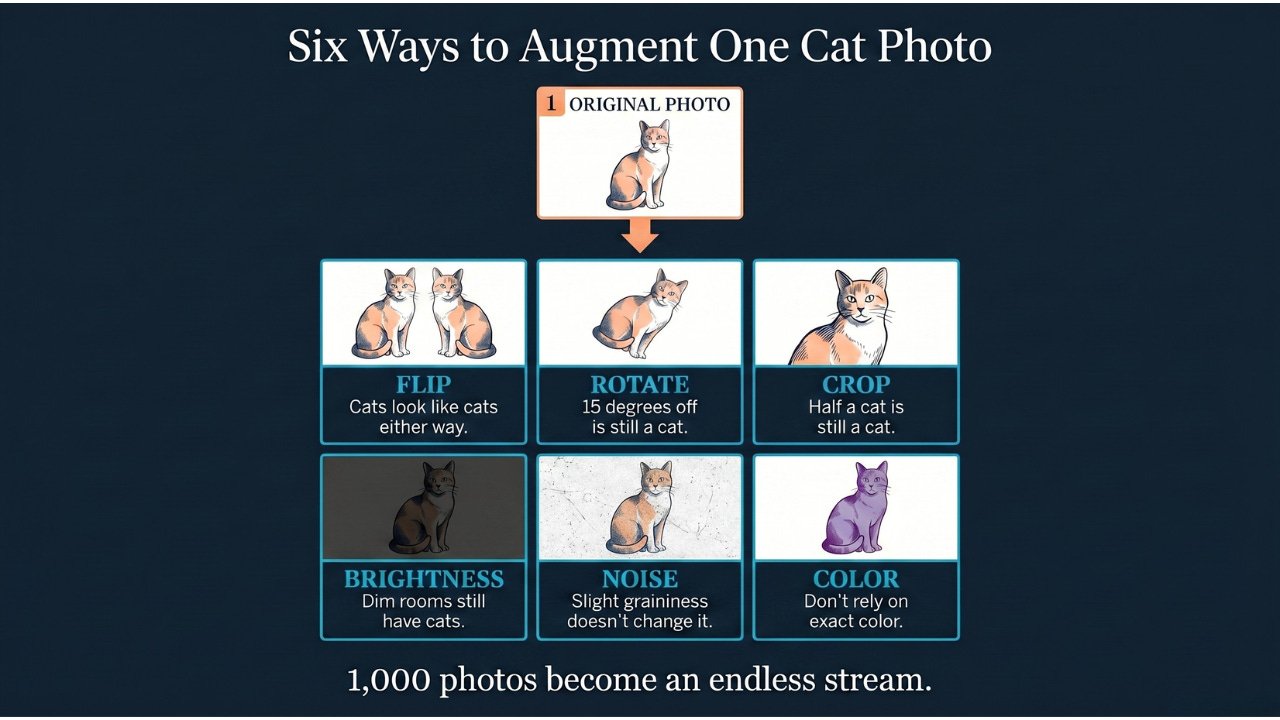
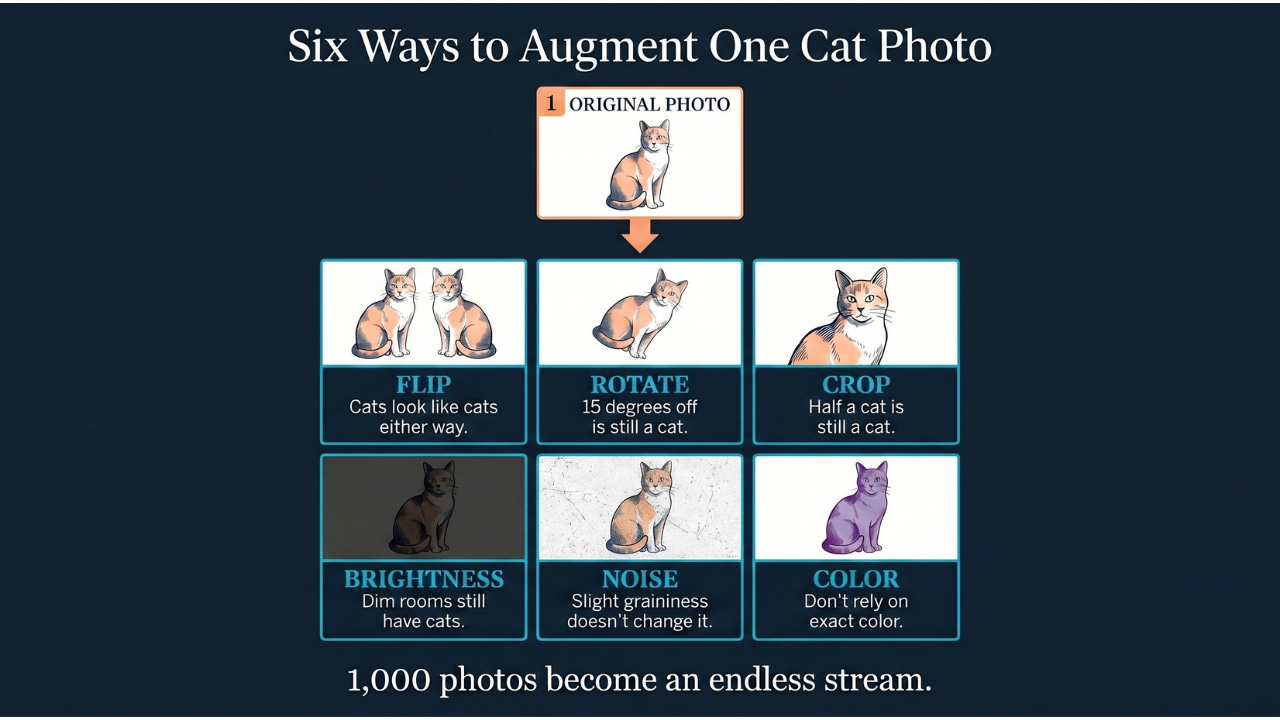
For an image classifier training to detect cats, instead of showing the model the same cat photo over and over, you:
-
Flip it horizontally (cats look like cats whether facing left or right)
-
Rotate it slightly (a cat tilted 15 degrees is still a cat)
-
Crop it to different portions (a cat partially out of frame is still a cat)
-
Adjust the brightness up or down (cats in dim rooms are still cats)
-
Add a small amount of random noise (slight graininess doesn’t change what it is)
-
Adjust the color slightly (the model shouldn’t rely on exact color values)
Each of these modified versions is treated as a new training example. And because the augmentations are typically applied fresh and randomly every time the model studies the data, the model effectively never sees the exact same example twice. Your original 1,000 photos become an essentially endless stream of variations, all from the same source material.’
The model sees so many variations of each example that it becomes very difficult to memorize any specific one. Instead, it has to learn what’s actually essential: the shapes, structures, and patterns that make something a cat under any conditions.
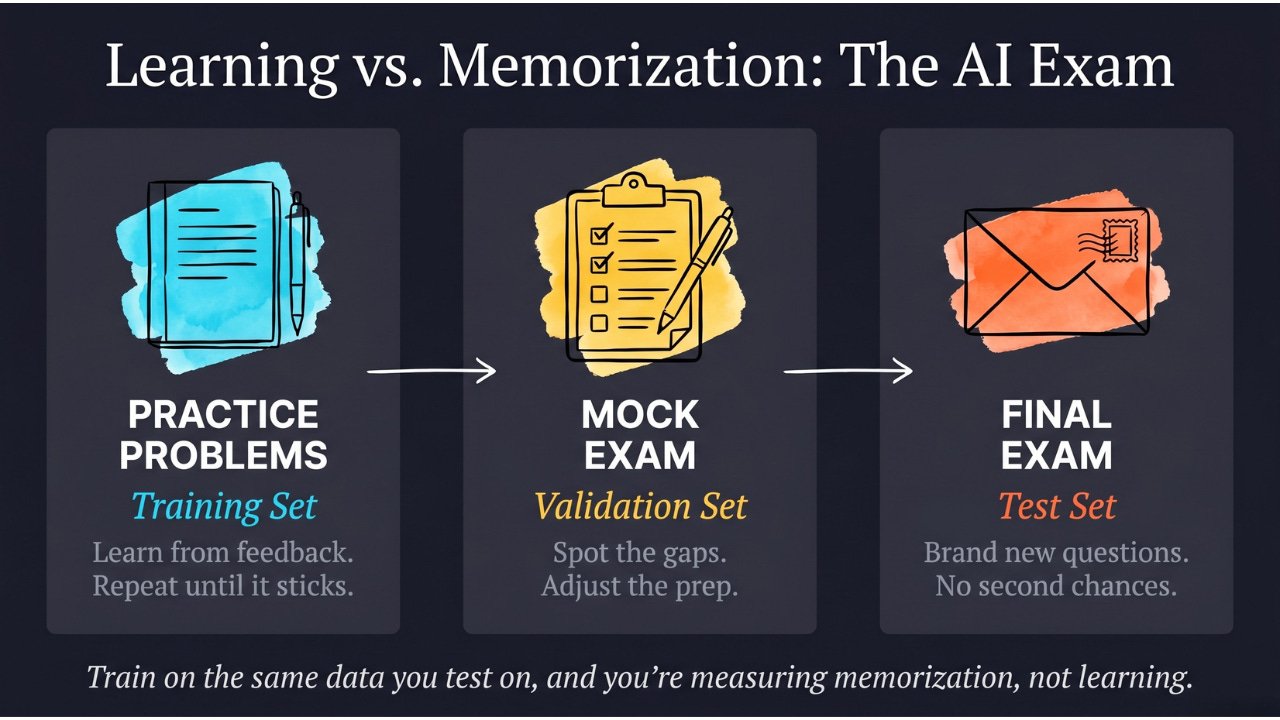
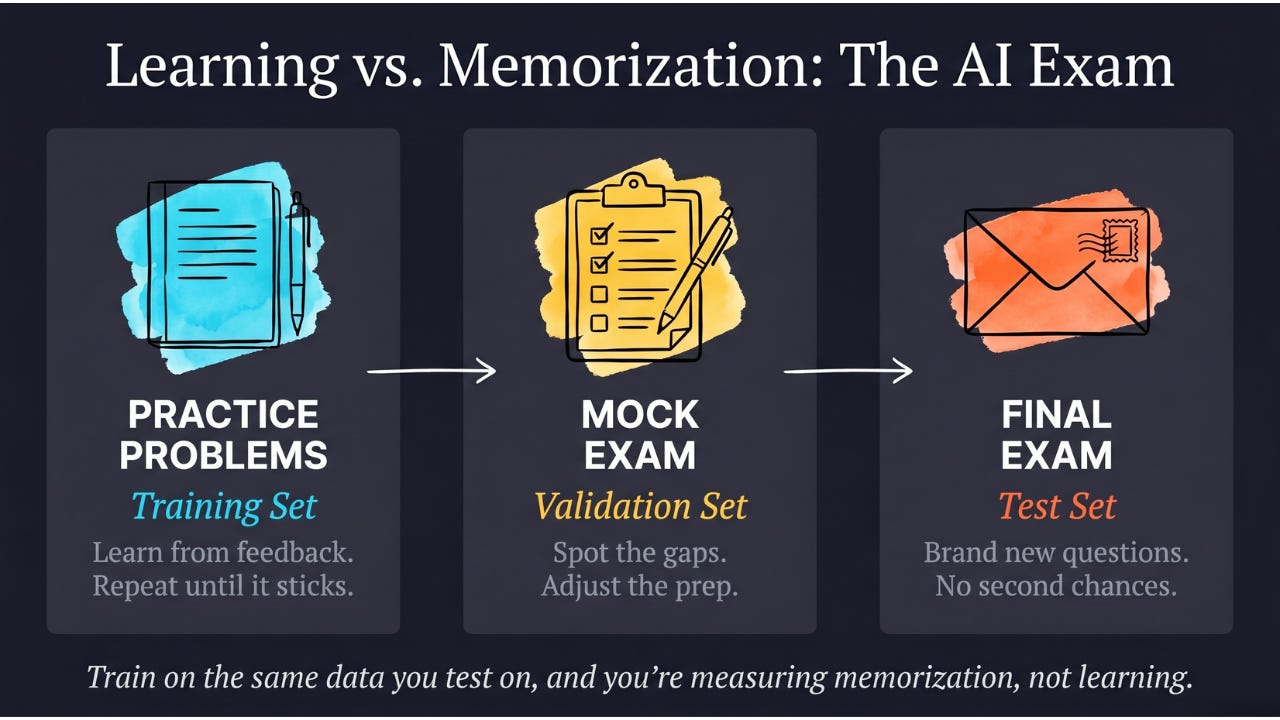
Why This Fights Overfitting
We covered overfitting earlier — when a model memorizes its training data instead of learning generalizable patterns.
Data augmentation directly attacks this problem. If every time the model sees a training example it looks slightly different, the model can’t memorize the specific pixel values. It’s forced to learn deeper patterns that hold across all the variations.
It’s like the difference between studying for an exam by memorizing sample questions versus studying by deeply understanding the underlying concepts. The model that memorizes exact training images will fail on slightly different real-world images. The model that’s learned through augmented variations has encountered so much variety that new real-world images feel familiar.

Augmentation Beyond Images
Data augmentation was pioneered in computer vision, but it’s now applied across every type of data.
Text augmentation: For natural language processing (NLP) tasks, you might replace words with their synonyms, randomly swap sentence order, or translate text to another language and back. If a model learns to classify “customer is upset” as negative sentiment, it should also classify “client is dissatisfied” the same way, augmentation teaches it to.
Audio augmentation: For speech recognition models, you augment recordings by adding background noise, changing the pitch slightly, adjusting playback speed, or simulating different room acoustics. A voice assistant that only trains on clean recordings in a quiet room will struggle in a noisy kitchen, augmentation with realistic noise conditions fixes this.
Time-series augmentation: For financial or sensor data, you apply small shifts in timing, add realistic noise to readings, or slightly scale numerical values, teaching the model to recognize patterns regardless of minor variations in measurement conditions.
And the frontier keeps moving. The newest forms of augmentation don’t just modify existing examples — they use AI itself to generate entirely new training data, mixing pieces of one example with another, or producing fully synthetic examples that never existed in the real world. The line between “modifying” data and “creating” it is blurring fast.
The Practical Impact
The difference data augmentation makes is most dramatic when training data is scarce, which is most of the time in specialized domains.
Medical imaging: In a landmark 2017 study at Stanford, researchers trained a skin cancer detection model without millions of labeled dermatology images. They had thousands. Data augmentation — flipping, rotating, zooming, adjusting color balance — expanded their effective training set dramatically. The resulting model matched dermatologist performance in studies.
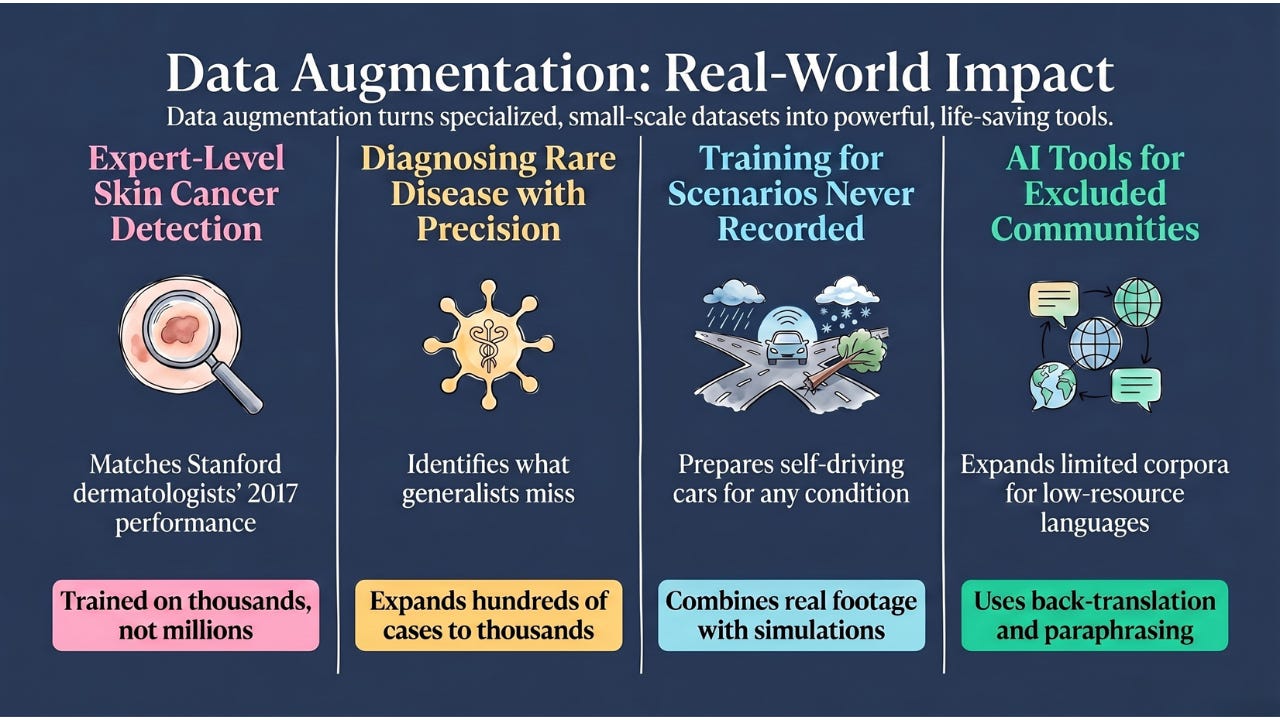
Rare disease diagnosis: For conditions where only hundreds of confirmed cases exist in the medical literature, augmentation allows AI models to train on those cases from many angles rather than overfitting to the specific examples available.
Self-driving vehicles: Companies like Waymo expand their training data with simulated weather conditions, lighting changes, unusual road configurations, and rare events (a bicycle falling in front of the car, a pedestrian in an unexpected location). This blends classical augmentation of real footage with simulation of scenarios that never actually happened, so the car can encounter a real-world situation it’s never literally seen because it’s been trained on the simulated version.
Low-resource languages: For languages with limited text data for NLP training, augmentation techniques that paraphrase, restructure, or back-translate (translating to another language and then back to the original) can expand training sets dramatically, making language tools available for communities that would otherwise be excluded.
The Limits
Data augmentation is a tool, not a miracle.
The augmentations you apply have to be meaningful. Flipping a cat photo horizontally makes sense — cats are symmetric in important ways. Flipping a chest X-ray, on the other hand, can introduce misleading artifacts: the human body isn’t symmetric on the inside. The heart usually sits on the left, the liver on the right, the stomach on the left. A horizontally-flipped X-ray quietly creates a patient whose anatomy doesn’t exist.
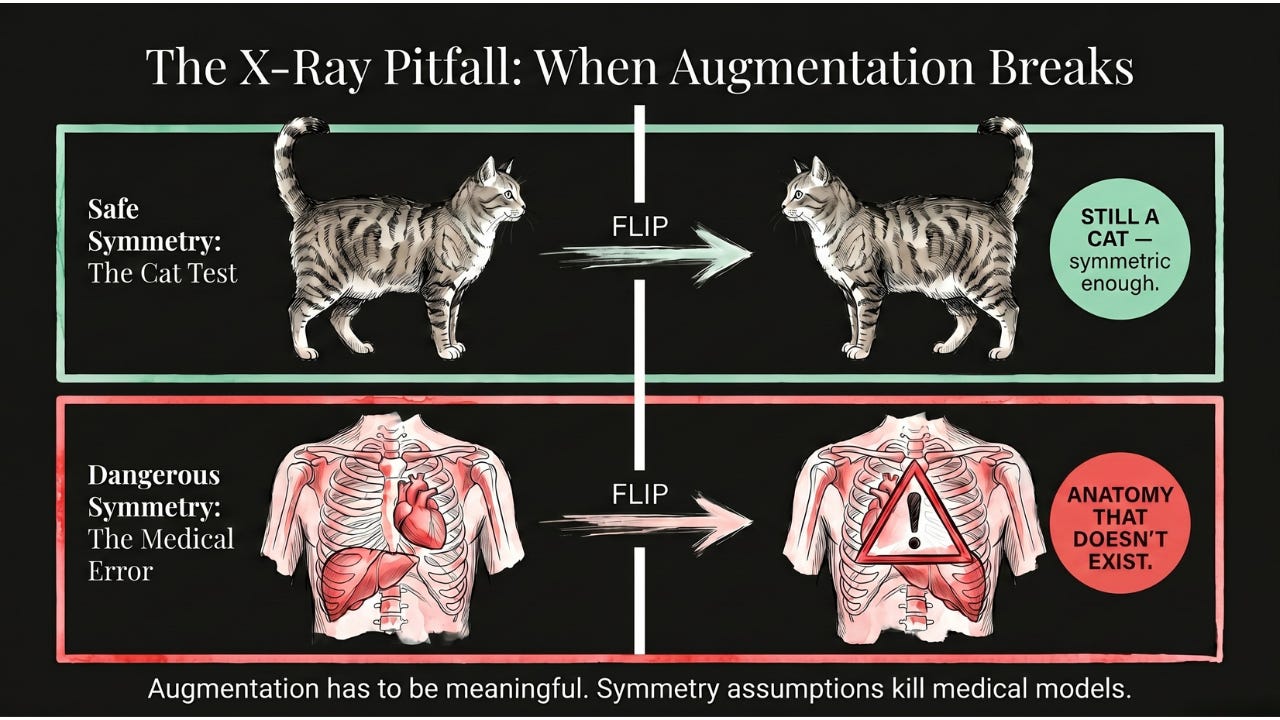
Augmentation can’t substitute for genuine data diversity. If all your cat photos are of domestic shorthairs, augmenting them won’t teach the model to recognize Maine Coons. The variations you generate are bounded by the original examples.
And too much augmentation can sometimes hurt. If augmentations are so extreme they change the character of what the example represents, distorting a photo until it no longer looks like a cat, you’re training on misleading examples.
The art is in choosing augmentations that reflect the real-world variation the model will encounter, without introducing variations that misrepresent the underlying concepts.
The Takeaway
Data augmentation is how AI learns to see the world through all its variations, not just the specific examples it was shown.
By creating modified versions of training examples, flipped, rotated, brightened, noised, paraphrased, you give the model a broader view of the underlying patterns. It becomes harder for the model to memorize specific examples and easier for it to generalize to new ones.
It’s one of the simplest ideas in the field with one of the most reliable returns. More training variety, for free, from the data you already have.
Coming Up
Data augmentation gives the model more variety in what it learns from. But there’s another question hiding right next to it: how should the model actually study all that data? Should it adjust itself after every single example, or wait until it’s read everything, or somewhere in between?
Turns out the answer is a careful middle path called batch learning, and it shapes how every modern AI model gets trained. Next edition: why AI doesn’t study the whole library before forming an opinion, but also doesn’t change its mind after every single page.
Was this helpful? Does the music student analogy capture how augmentation works for you? Reply and let us know.
AI for Common Folks — Making AI understandable, one concept at a time.