
A Model in AI is the result of training — a saved file containing all the patterns, rules, and mathematical weights a computer learned from data, ready to make predictions on new information.
Hey Common Folks!
We’ve covered the umbrella (AI), the engine (Machine Learning), how computers learn (Deep Learning), the fuel (Data Science), and the three ways AI learns (Supervised, Unsupervised, and Semi-Supervised).
But when you open ChatGPT, or when Netflix recommends a movie, or when your bank approves a loan — what are you actually interacting with?
You’re interacting with The Model.

In the AI world, people often confuse “Algorithm” and “Model.” They use them interchangeably, like “Engine” and “Car.” But they’re different things. Today, we’re defining exactly what a Model is, because this is the “product” that companies are actually building, selling, and competing over.
The Analogy: The Student and the Exam
Think about a student preparing for a math exam.
-
The Study Method (Algorithm): How the student learns — flashcards, practice problems, tutoring. This is the process of improving.
-
The Textbooks (Training Data): The material they study from.
-
The Student on Exam Day (Model): Once studying is done, they walk into the exam. They’re not holding the textbook anymore. They’re holding the knowledge in their head.
The Model is the student’s brain after they’ve finished studying.
When you ask ChatGPT a question, you’re not running the training process again. You’re asking the “graduated student” to use what they already know to give you an answer.
What Does a Model Actually Look Like?
If you could crack open an AI model file (like a .bin or .pytorch file) and peek inside, what would you see?
Not miniature brains. Not videos.
Numbers. Billions of them.

A model is simply a Parameterized Math Function. Remember high school math?
Where:
-
x is the input (e.g., house size)
-
y is the output (e.g., house price)
-
m and b are the Parameters (the learned values)
When we “train a model,” we’re finding the perfect numbers for m and b so the equation fits the data accurately.
-
In a simple model: You might have 2 parameters
-
In GPT-4: You have hundreds of billions of parameters
The “Model” is just that massive list of numbers saved in a specific structure. That’s it.
The Three Stages of a Model’s Life
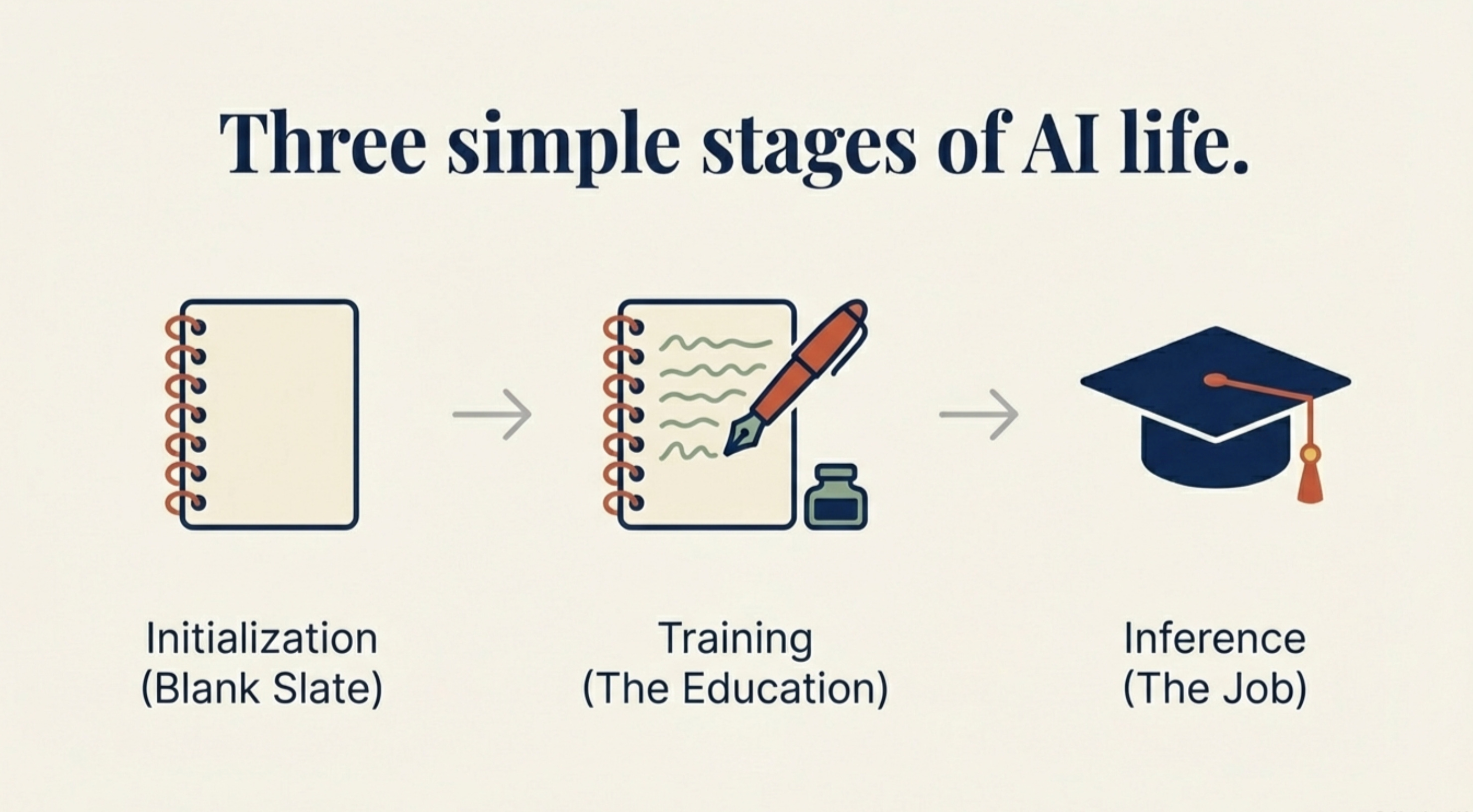
Every model goes through this lifecycle:
1. Initialization (The Blank Slate)
We create the architecture (the structure), but it knows nothing. The weights are random numbers. It’s essentially a baby brain.
2. Training (The Education)
We feed it data. The model makes a guess, gets it wrong, and the algorithm adjusts those numbers slightly. This happens millions of times until accuracy improves.
3. Inference (The Job)
Training is done. We “freeze” the numbers — they stop changing. This static file (the trained model) goes into an app. When you type a prompt, the model uses those frozen numbers to calculate an answer.
Why Are Some Models “Smarter”?
Why is GPT-4 smarter than a simple spam filter?
It comes down to Capacity:
Shallow Models (Simple):
-
Like Linear Regression — draws a straight line through data
-
Great for simple predictions (house prices based on square footage)
-
Fails at complex tasks
Deep Models (Complex):
-
Like Deep Neural Networks — many layers stacked together
-
Can learn incredibly complex patterns
-
Powers language understanding, image recognition, creative generation
More parameters + more layers + more training data = more capable model.
Models You Use Every Day

-
ChatGPT / Claude / Gemini: Large Language Models (LLMs) with billions of parameters
-
Face ID: A vision model that learned your facial features
-
Spotify Discover Weekly: A recommendation model predicting what you’ll enjoy
-
Google Search: Multiple models ranking and understanding your queries
The Limitations (Keeping It Real)
Models aren’t magic — they have real constraints:
Only as good as their data: A model trained on biased data learns biased patterns.
Frozen knowledge: Once trained, a model doesn’t learn new things unless retrained. That’s why ChatGPT has a “knowledge cutoff.”
Black boxes: Complex models often can’t explain why they made a decision. They just… work.
Size vs. speed tradeoff: Bigger models are smarter but slower and more expensive to run.

The Takeaway
When you hear “OpenAI released a new model,” translate that in your head to:
“OpenAI finished training a massive mathematical function and saved the resulting list of numbers into a file that we can now use.”
-
Algorithm: The recipe for learning
-
Data: The ingredients
-
Model: The finished cake
You eat the cake, not the recipe. You use the model, not the training process.
Coming Up:
Now that you know what a Model is, how does it actually learn? In the next edition, we’ll explore Algorithms — the step-by-step processes that turn raw data into intelligent models.
AI for Common Folks — Making AI understandable, one concept at a time.
Leave a Reply