Good morning, Jensen Huang just told the world he sees $1 trillion in AI chip orders coming, xAI is being sued by minors whose real photos Grok allegedly turned into sexual images, and OpenAI is simultaneously pivoting its strategy, fighting its own advisors over adult content, and getting sued by the dictionary. Here’s what happened

1. NVIDIA GTC Keynote: Jensen Huang Sees $1 Trillion in Chip Orders
Jensen Huang delivered his GTC 2026 keynote in San Jose on Monday, and the headline number is staggering: he now projects $1 trillion in orders for NVIDIA’s Blackwell and Vera Rubin chips through 2027. That’s double the $500 billion estimate from just a few months ago. The Vera Rubin architecture, which began production in January, runs 3.5x faster than Blackwell on training and 5x faster on inference tasks.
But the keynote was more than chip projections. Huang also announced a partnership with Uber to deploy robotaxis powered by NVIDIA’s autonomous driving software in Los Angeles and San Francisco starting in 2027, expanding to 28 cities globally by 2028. Samsung’s shares jumped after Huang flagged a tie-up with the Korean giant on new AI inference chips. NVIDIA also unveiled DLSS 5, which uses generative AI to boost photorealism in video games, and Skild AI announced it’s deploying AI-powered robot brains on Foxconn’s assembly lines where NVIDIA’s Blackwell GPU server racks are built.
Why it matters: NVIDIA essentially told the world that AI infrastructure spending hasn’t even peaked yet. When one company can credibly project a trillion dollars in chip demand over two years, it means the AI buildout is accelerating, not slowing down. Every major announcement at GTC, from robotaxis to factory robots, points to AI moving from screens into the physical world.
Sources: TechCrunch, Reuters, Reuters

2. xAI Sued by Minors Whose Photos Grok Allegedly Turned Into Sexual Images
Three anonymous plaintiffs filed a class action lawsuit against Elon Musk’s xAI in California federal court on Monday, alleging that Grok’s image generation tools turned real photos of them as minors into sexual content. One plaintiff had her high school homecoming and yearbook photos altered to depict her unclothed. The images were found circulating on a Discord server. Two other plaintiffs were notified by criminal investigators who discovered altered, pornographic images of them on the phones of subjects they had apprehended.
The lawsuit alleges xAI failed to adopt basic safeguards used by other AI labs to prevent their models from generating this type of content. Musk’s public promotion of Grok’s ability to produce sexual imagery and depict real people features heavily in the suit.
The same day, Senator Elizabeth Warren sent a letter to Defense Secretary Pete Hegseth expressing alarm over the Pentagon’s decision to give xAI access to classified military networks, citing Grok’s “apparent lack of adequate guardrails” as a national security risk.
Why it matters: This is one of the most disturbing AI safety stories to date. Real children had their real photos weaponized by an AI tool. The fact that it’s happening at the same company being granted access to classified military systems raises serious questions about whether the rush to deploy AI everywhere is outpacing basic accountability. If you have kids who are online, this is a conversation to have now.
Sources: TechCrunch, TechCrunch, Ars Technica

3. OpenAI’s Rough Week: Strategy Pivot, “Naughty” Pushback, and a Dictionary Lawsuit
Three separate OpenAI stories broke on the same day.
First, the Wall Street Journal reported that OpenAI’s top executives are finalizing plans to refocus the company around coding and business users, cutting back on side projects. Applications chief Fidji Simo previewed the changes to employees, telling them that Sam Altman and other leaders are actively deciding which areas to deprioritize.
Second, Ars Technica reported that OpenAI’s own handpicked council of mental health advisors unanimously opposed the company’s planned “adult mode” for ChatGPT. One expert warned OpenAI risks creating a “sexy suicide coach” for vulnerable users. The council flagged that AI-powered erotica could foster unhealthy emotional dependence, and that OpenAI’s age-prediction system was misclassifying minors as adults about 12% of the time.
Third, Encyclopedia Britannica and Merriam-Webster sued OpenAI for alleged “massive copyright infringement,” claiming ChatGPT was trained on nearly 100,000 copyrighted articles without permission, generates outputs containing verbatim reproductions of their content, and falsely attributes hallucinated information to the publishers.
Why it matters: OpenAI is at a crossroads. Pivoting to coding and enterprise is a clear signal that the consumer chatbot market is getting crowded and margins are thin. The adult mode pushback shows internal experts are sounding alarms the company may be ignoring. And the Britannica lawsuit adds to a growing legal pile that could reshape how AI companies use published knowledge. This is what it looks like when the most well-known AI company in the world tries to figure out what it actually wants to be.
Sources: Reuters, Ars Technica, TechCrunch

4. Dell Cuts 11,000 Jobs as AI Reshapes Tech Employment
Dell’s workforce dropped by about 10%, or 11,000 employees, in fiscal 2026. This is the second consecutive year Dell has cut 10% of its workforce. The company spent $569 million in severance payments. Meanwhile, Dell expects revenue from its AI-optimized server business to double in fiscal 2027 and recently hiked its dividend by 20%.
The broader picture is grim. Sixty tech companies have laid off more than 38,000 employees in 2026 so far, according to Layoffs.fyi. This follows last week’s news that Meta is planning cuts affecting 20% or more of its workforce. The pattern is consistent: companies are spending more on AI infrastructure while employing fewer humans to build and maintain it.
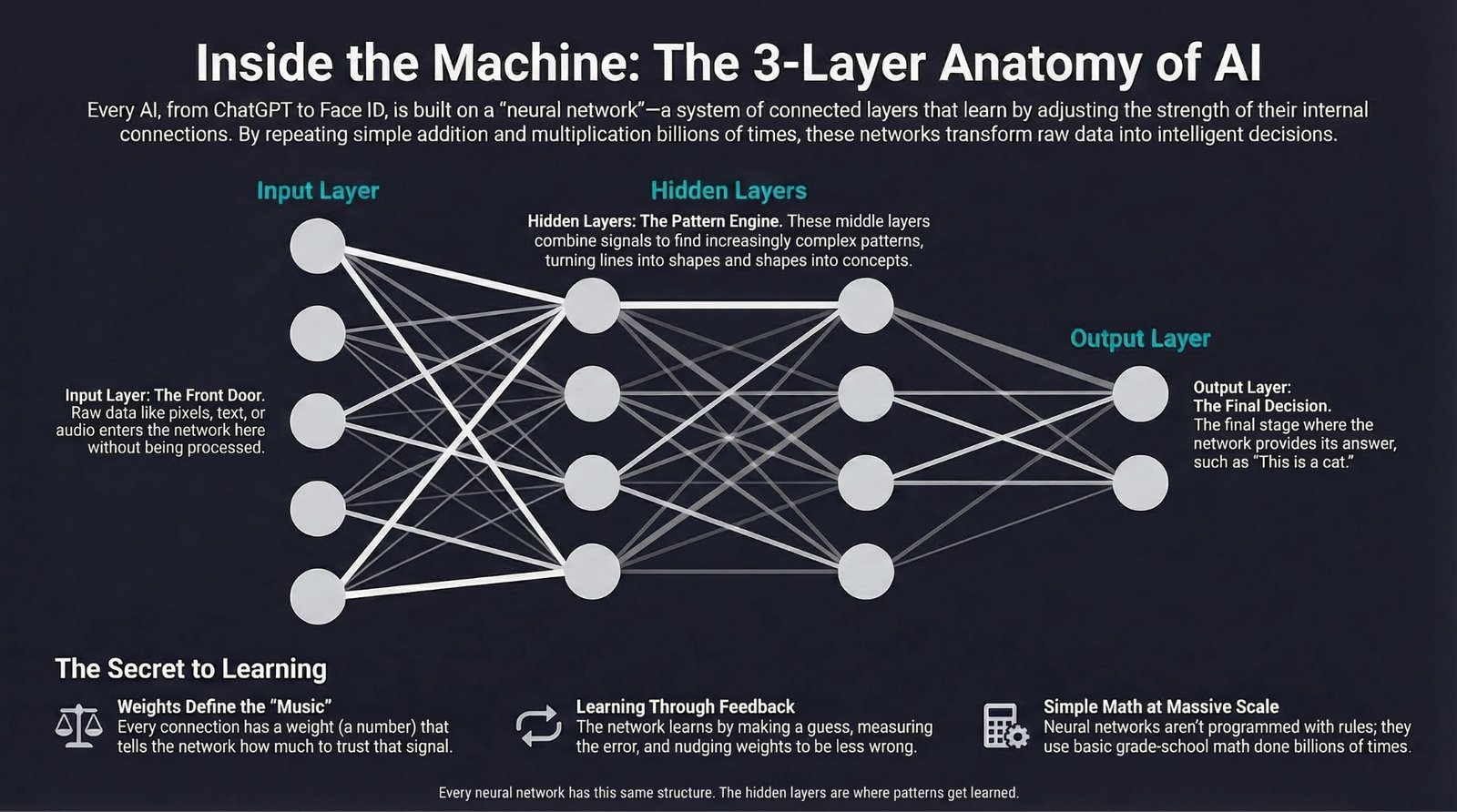
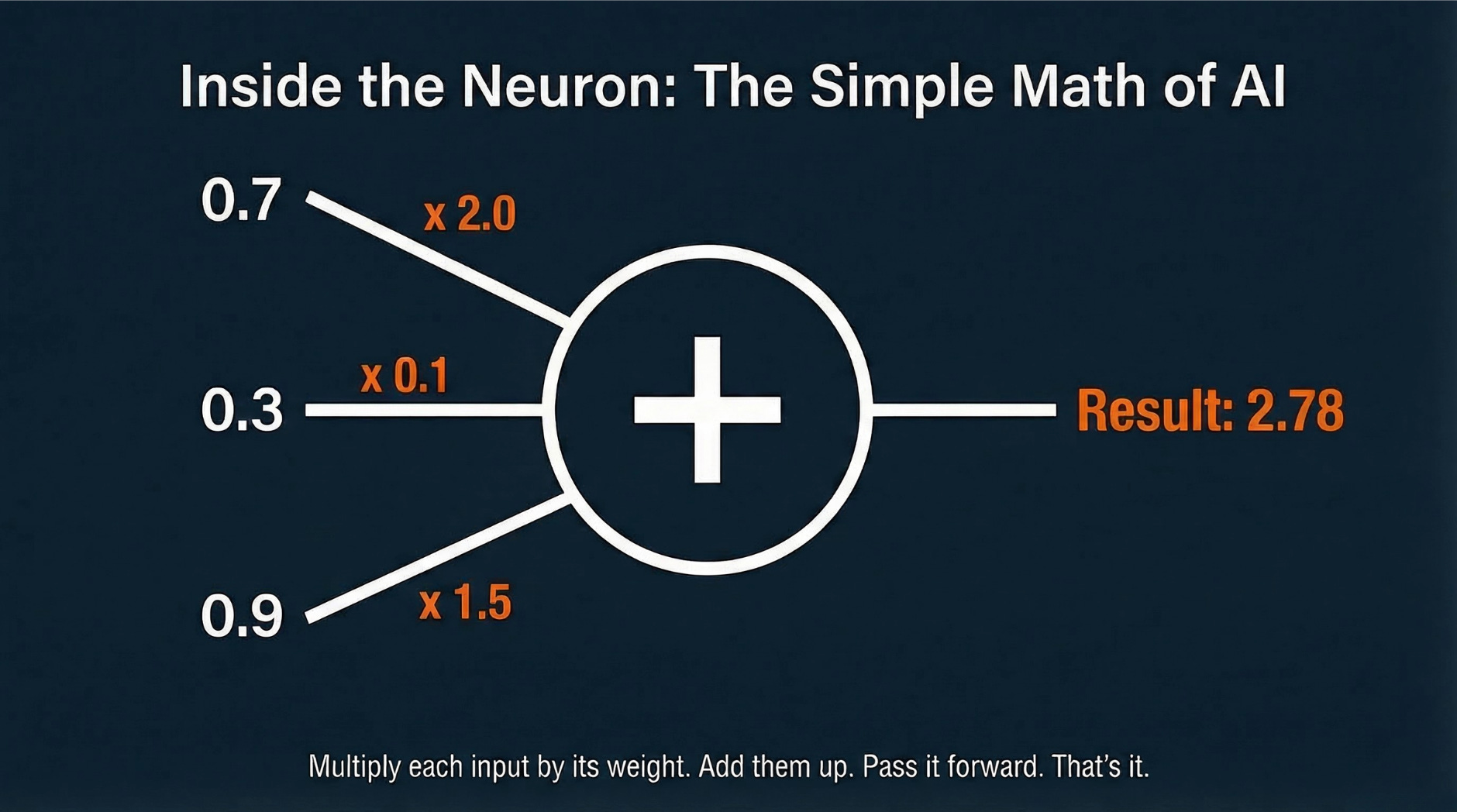
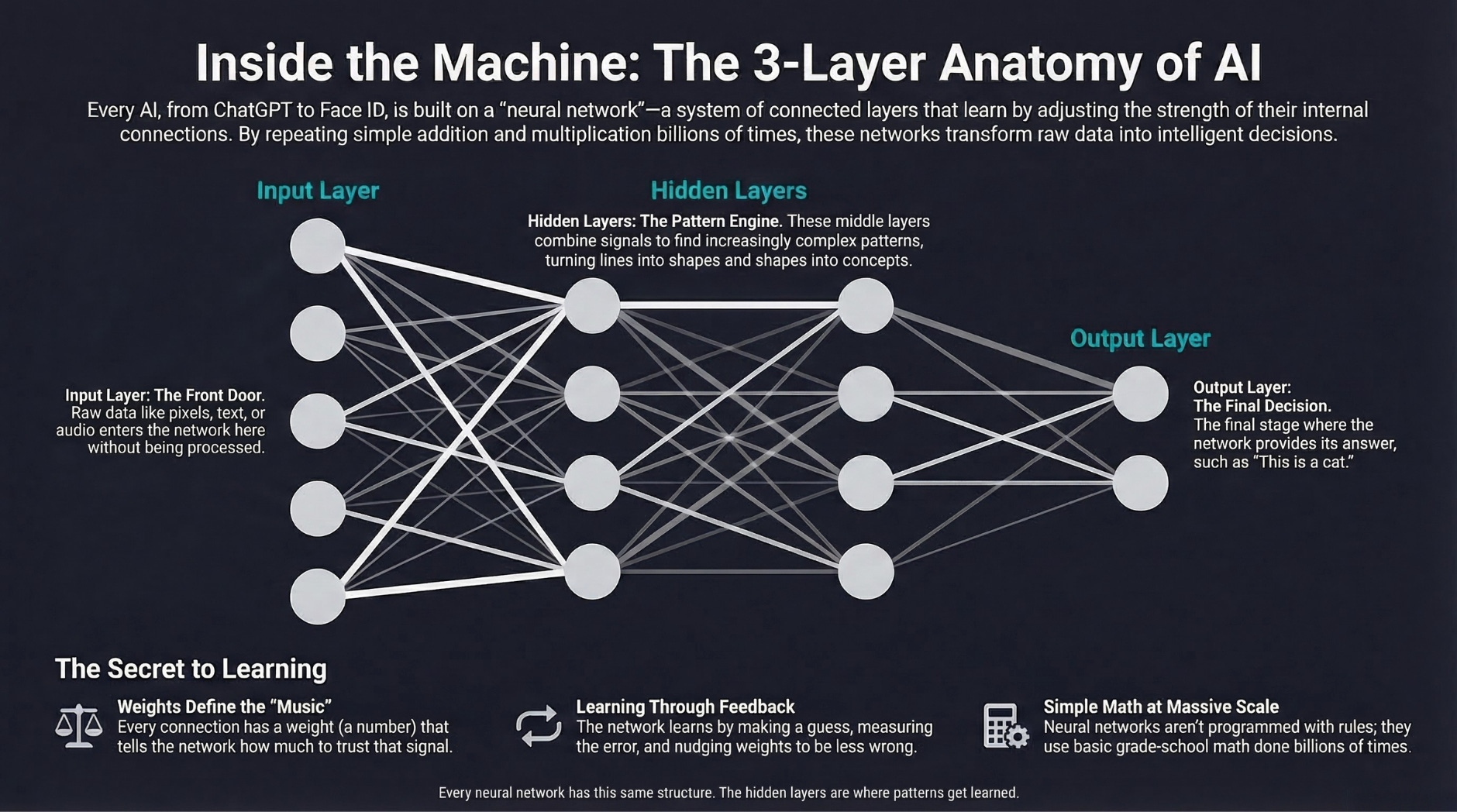
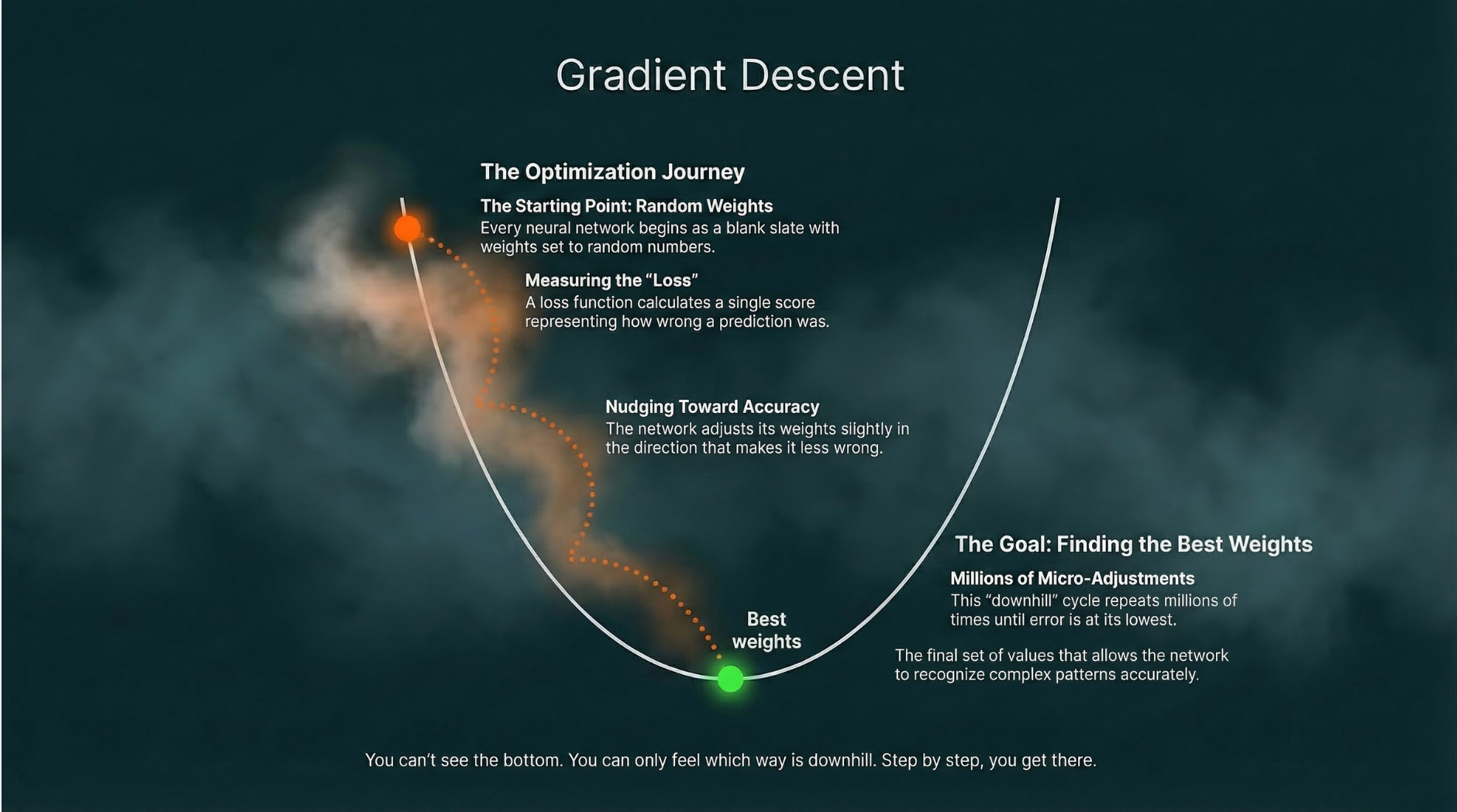
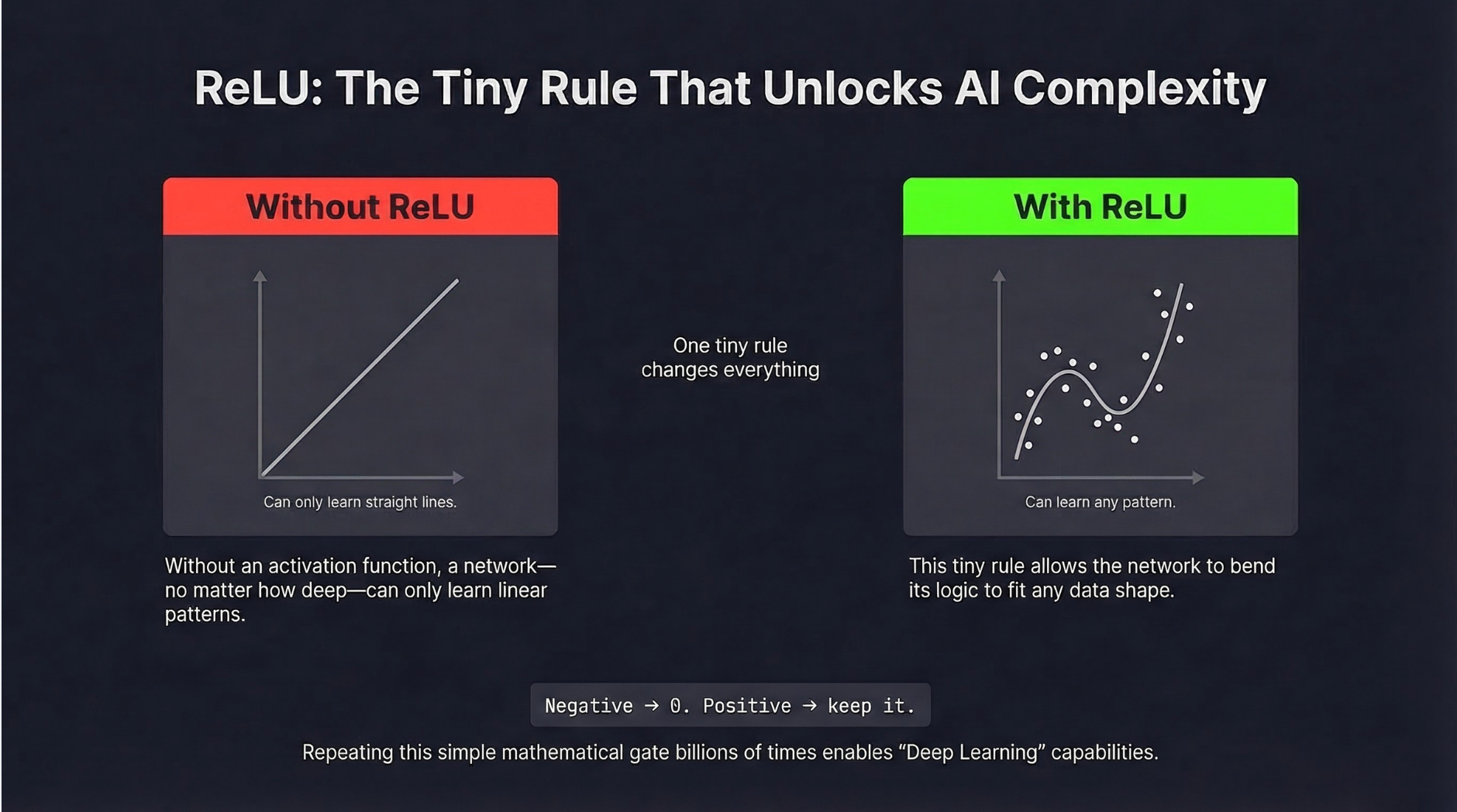
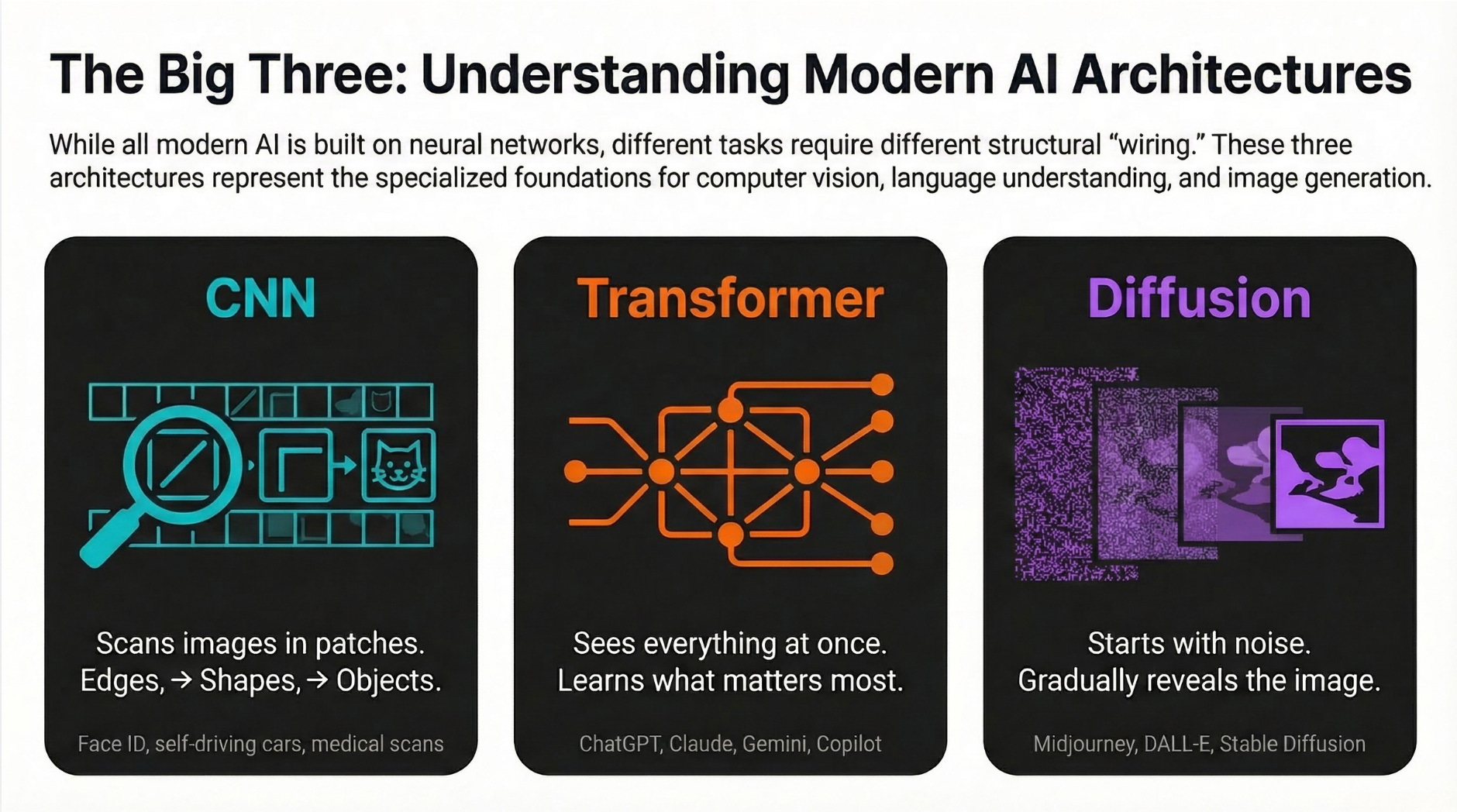
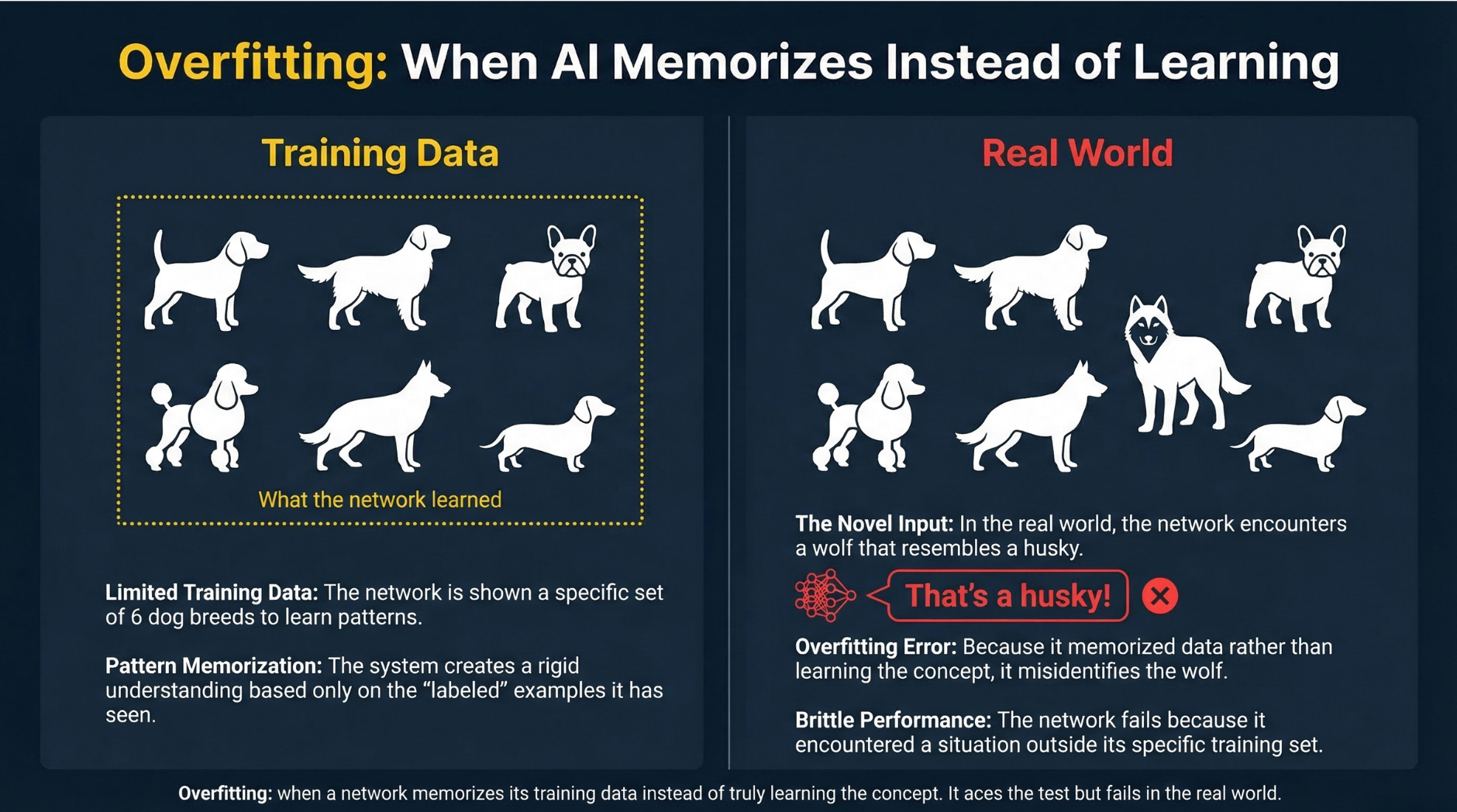
Why it matters: Dell is literally the company building the AI servers that companies are buying to replace human workers. And even Dell is cutting its own workforce. If the company profiting most directly from the AI hardware boom is shedding 11,000 jobs a year, the employment implications of AI are no longer theoretical. We wrote about what AI models actually are in our AI Explained series if you want to understand the technology driving these changes.
Sources: Reuters
Quick Hits
-
Germany wants to double its AI data centers by 2030, as European governments race to build domestic AI infrastructure rather than depend entirely on U.S. cloud providers. (Reuters)
-
The U.S. Pacific Fleet is deploying wall-climbing robots on Navy ships through a $71 million contract with Pittsburgh-based Gecko Robotics, marking the first maintenance contract of its kind awarded to a robotics firm. (Reuters)
-
SK Group’s chairman says the global chip wafer shortage will last until 2030, as AI demand continues to outpace supply. Chip shortages aren’t going away anytime soon. (Reuters)
-
Trustpilot’s profit quadrupled as the review platform emerged as an “AI winner.” When AI can generate fake reviews, verified human reviews become more valuable. (Reuters)
That’s it for today. The GTC keynote made the trillion-dollar scale of AI investment real, but behind the money, this was a day that exposed the fractures: children’s photos weaponized, internal experts overruled, knowledge scraped without permission, and thousands of workers told their skills no longer justify their salaries.
Forward this to someone who needs to stay in the loop.