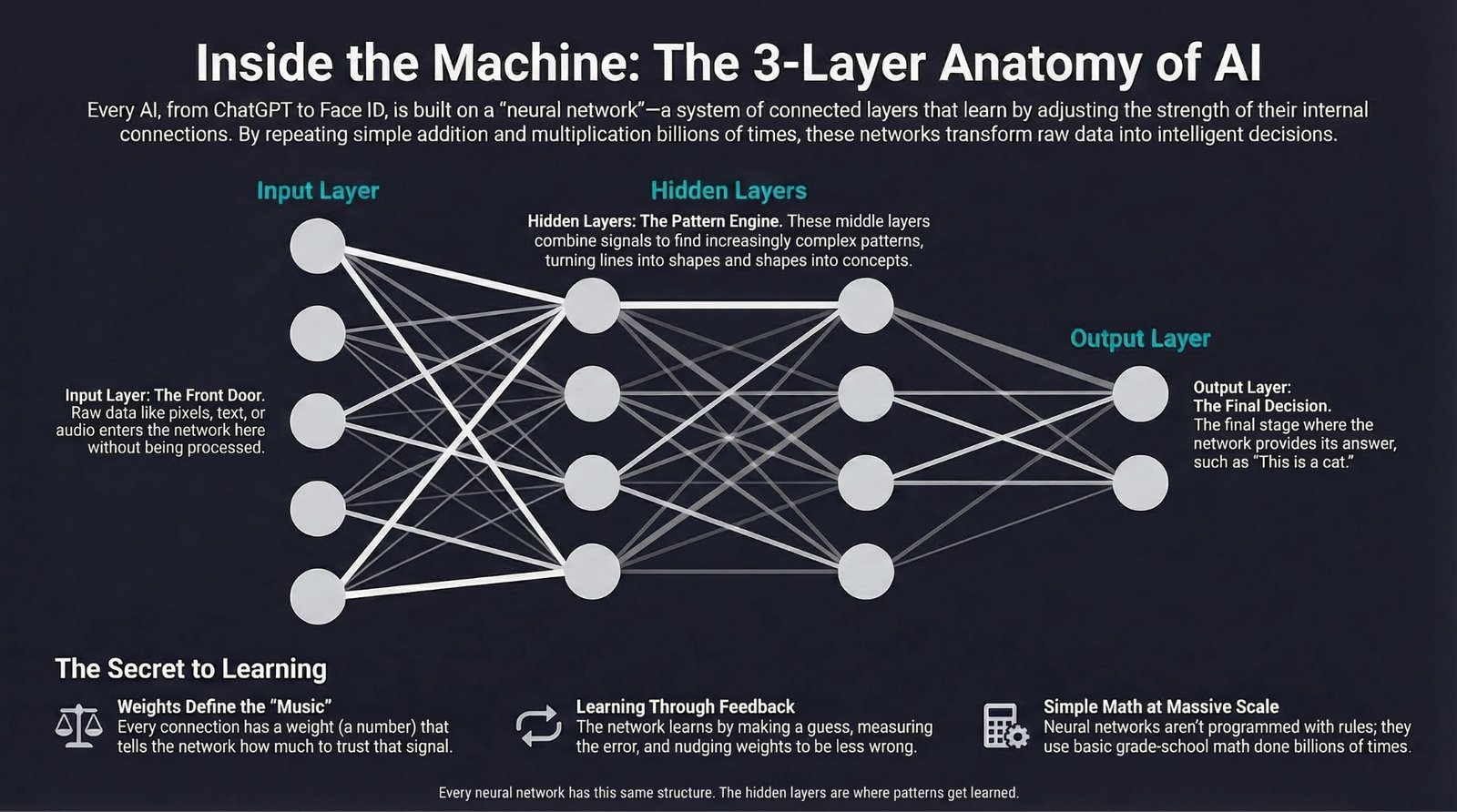
A neural network is a computing system made of layers of connected “neurons” that learns to recognize patterns by adjusting the strength of its connections, like a team that gets smarter every time it makes a mistake and corrects it.
Hey Common Folks!
Last time, we covered Semi-Supervised Learning, how AI can learn from a small number of labeled examples and a massive pile of unlabeled data.
But through all these conversations about how AI learns, one question keeps coming up:
What is the actual structure inside the machine doing all this learning?
When people say “the AI figured it out,” what is the it they’re referring to?
That’s a neural network. And once you understand what it is, everything else in AI (ChatGPT, Gemini, image generators, voice assistants) suddenly starts making sense.
The Big Reveal: It’s Simpler Than You Think
Here’s something the textbooks rarely tell you upfront.
When Jeremy Howard (founder of fast.ai, one of the most respected AI educators in the world) reveals how neural networks actually work to his students, the most common reaction is:
“Wait… is that ALL it is?”
Neural networks are powerful not because they’re mathematically exotic. They’re powerful because they do something incredibly simple an incredibly large number of times.
Almost everything a neural network does is just addition and multiplication. A lot of it. Done very fast.
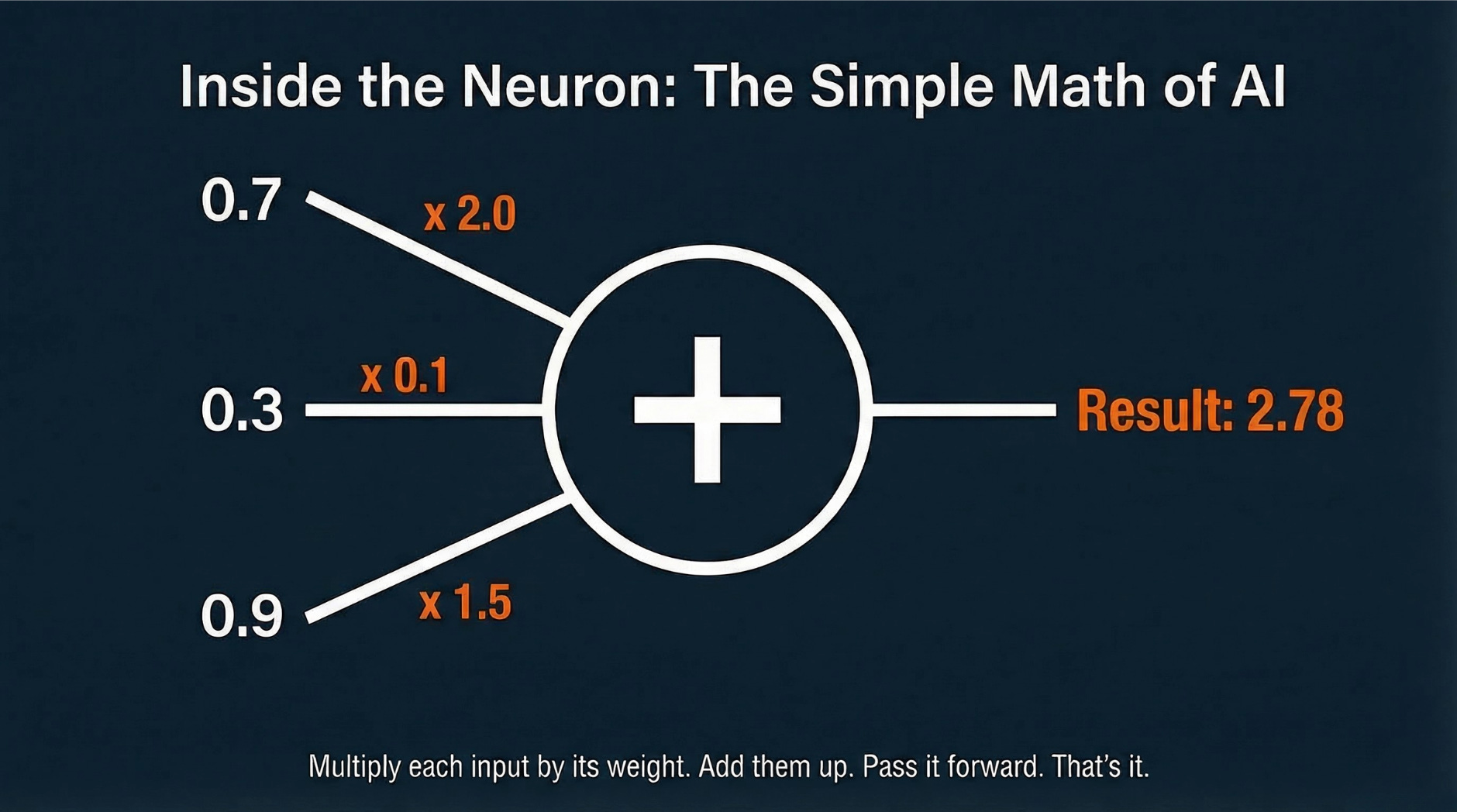
What does that look like? Each unit in the network takes incoming signals (numbers), multiplies each one by a “weight” (a number that says how important that signal is), adds all the results together, and passes the total to the next layer. That’s it. Billions of tiny calculators doing grade-school math, over and over.
That’s the secret. Let’s build up to it.
The Analogy: Learning to Recognize Your Friend’s Face
Imagine you’re teaching a child to recognize your friend Sarah from a photo.
You show them 100 photos, some with Sarah, some without, and tell them “this is Sarah” or “this isn’t Sarah” for each one.
The child’s brain starts noticing patterns: Sarah has curly red hair. Her eyes are green. She usually smiles with her teeth.
At first, the child guesses wrong a lot. But every time you correct them, their brain quietly adjusts which features it pays attention to. Curly hair gets more weight. Background color gets less weight.
After enough photos, the child becomes pretty reliable.
A neural network does exactly this. Just with numbers instead of a child’s brain, and millions of examples instead of 100 photos.
The Three Parts of Every Neural Network
Every neural network in the world, from the tiny one in your spam filter to the massive one behind ChatGPT, has the same three-part structure.
1. The Input Layer: “Here’s What I’m Looking At”
This is where raw data enters the network.
-
For an image: each pixel becomes a number (0 = black, 255 = white), and each number enters here
-
For text: each word or piece of a word enters here
-
For audio: sound frequencies enter here
Nothing clever happens in the input layer. It’s just the front door.
2. The Hidden Layers: “Where the Magic Happens”
This is where the network learns patterns. Each hidden layer takes the previous layer’s output and transforms it, mixing and combining signals to find increasingly complex patterns.
Think of it in stages:
-
First hidden layer: detects simple features (”there’s a curved line here”)
-
Second hidden layer: combines those into shapes (”those curves form an ear”)
-
Third hidden layer: combines shapes into concepts (”that ear + those eyes = a face”)
The more hidden layers, the more complex the patterns the network can learn. This is why we call it deep learning: the network goes deep with many layers.
Modern AI systems have hundreds or even thousands of hidden layers.
3. The Output Layer: “Here’s My Answer”
The final layer makes a decision:
-
“This image is a cat” (classification)
-
“The next word is ‘the’” (language generation)
-
“The sentiment of this review is positive” (analysis)
-
“This email is spam” (filtering)
The Real Secret: Weights
Here’s the math secret, and it’s not scary.
Every connection between two neurons has a weight: a single number that says how much to trust that connection.
A weight of 2.0 means “pay close attention to this signal.”
A weight of 0.1 means “barely consider this signal.”
A weight of -1.5 means “this signal actually points the other direction.”
The entire job of training a neural network is just this: find the right numbers for every weight.
A typical large language model like Claude or GPT-4 has hundreds of billions of these weights. But each individual weight is still just a number, and finding the right set of numbers is what training is all about.
Think of it this way: the architecture is the instrument, and the weights are the music. Change the weights, and you’ve changed what the network does.
How It Learns: Hiking Downhill in the Fog
Here’s the part most people get wrong: neural networks aren’t programmed with rules. Nobody sat down and typed “if pointy ears AND whiskers, then cat.” The network figures out the rules itself, from examples.
Here’s how:
1. Start random. Every weight is set to a random number. The network starts as dumb as possible.
2. Make a prediction. Feed it an image. It guesses. Probably wrong.
3. Measure how wrong. A “loss function” calculates a single number representing the error, basically a score for how bad the answer was. High loss = very wrong. Zero loss = perfect.
4. Figure out which direction to improve. Using math called gradient descent, the network calculates: “If I increase this weight slightly, does the loss go up or down? Which direction makes me less wrong?”
The best analogy: hiking downhill in the fog. You can’t see the bottom of the valley, but you can feel which way the ground slopes under your feet. You take a small step downhill. Then another. Over time, you find your way to the lowest point.
The “valley” is the best possible set of weights. The fog is the fact that there’s no shortcut. The network has to feel its way there.
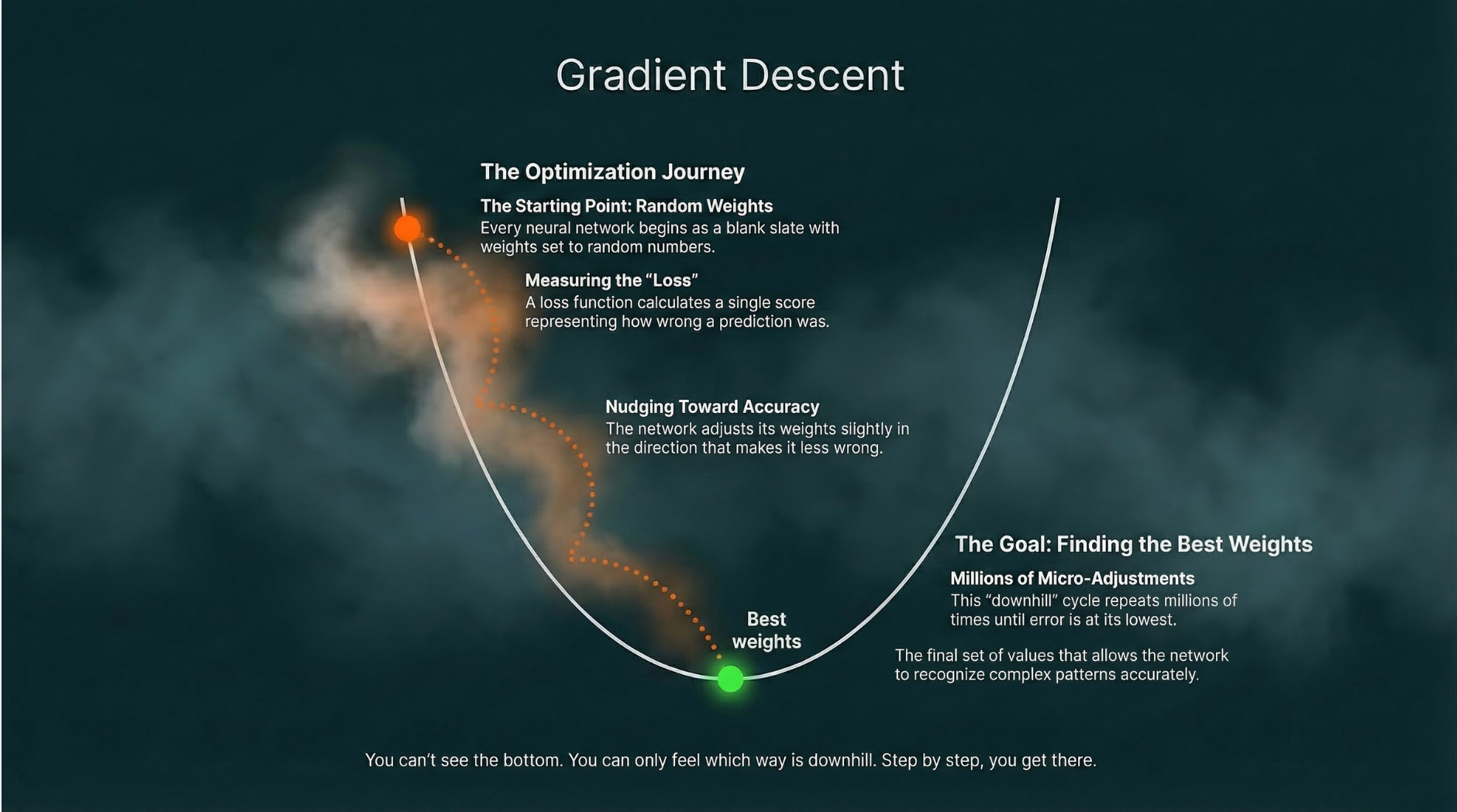
5. Adjust the weights. Nudge each weight slightly in the direction that reduces the loss.
6. Repeat millions of times. After enough examples and adjustments, the weights settle into values that make the network surprisingly accurate.
And here’s the thing: gradient descent nearly entirely relies on addition and multiplication. When students see the actual details, the most common reaction is: “Is that all it is?”
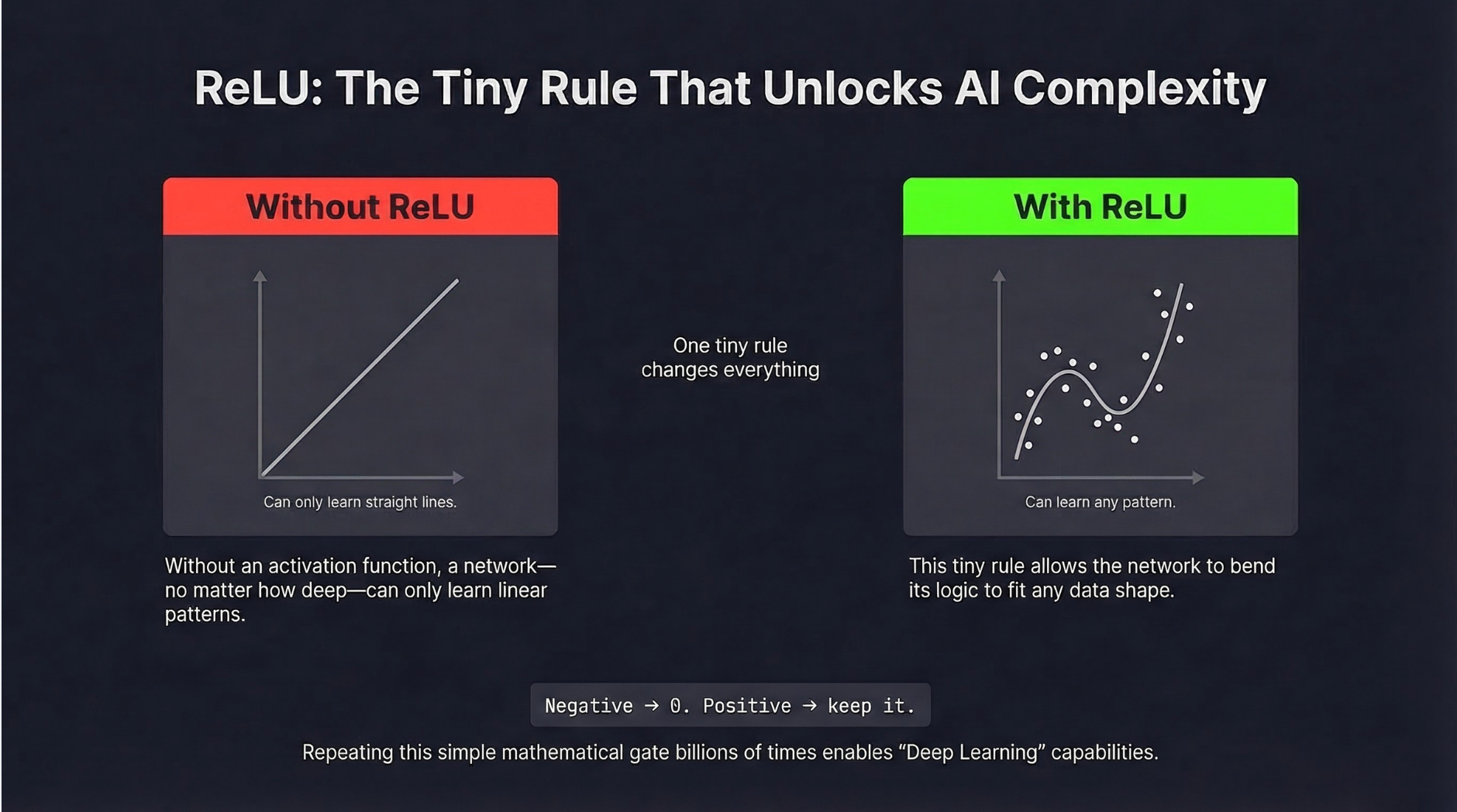
The Secret Ingredient: One Tiny Rule That Makes Everything Work
Here’s a surprising thing: if you just stack layers of math on top of each other with nothing in between, the whole thing collapses. It doesn’t matter if you stack 10 layers or 1,000. You end up with a network no smarter than a single layer. All that depth, wasted.
Imagine stacking 100 identical photo filters. The photo doesn’t get more detailed. It just gets darker. Same idea.
The fix is a tiny rule called an activation function, inserted between every layer. The most common one is called ReLU, and its entire job is this:
If the number coming in is negative, make it zero. If it’s positive, leave it alone.
That’s the whole rule. And that tiny step, repeated billions of times, is what gives neural networks the ability to learn curves, recognize faces, understand language, and generate images.
Here’s the intuition: without it, a network can only learn patterns that fit a straight line. With it, the network can bend and trace any shape, no matter how complex. The real world isn’t made of straight lines, so this matters enormously.
Different Networks for Different Jobs
As neural networks evolved, researchers found that different kinds of data work better with different structures. Here are the three types you’ll actually hear about:
CNNs: Built for Eyes
Convolutional Neural Networks are designed to look at images and video. They scan pictures in small patches, finding edges first, then shapes, then full objects, the same way your eye moves across a scene.
You use this: Apple Face ID, self-driving car cameras, doctors’ tools that detect tumors in scans.
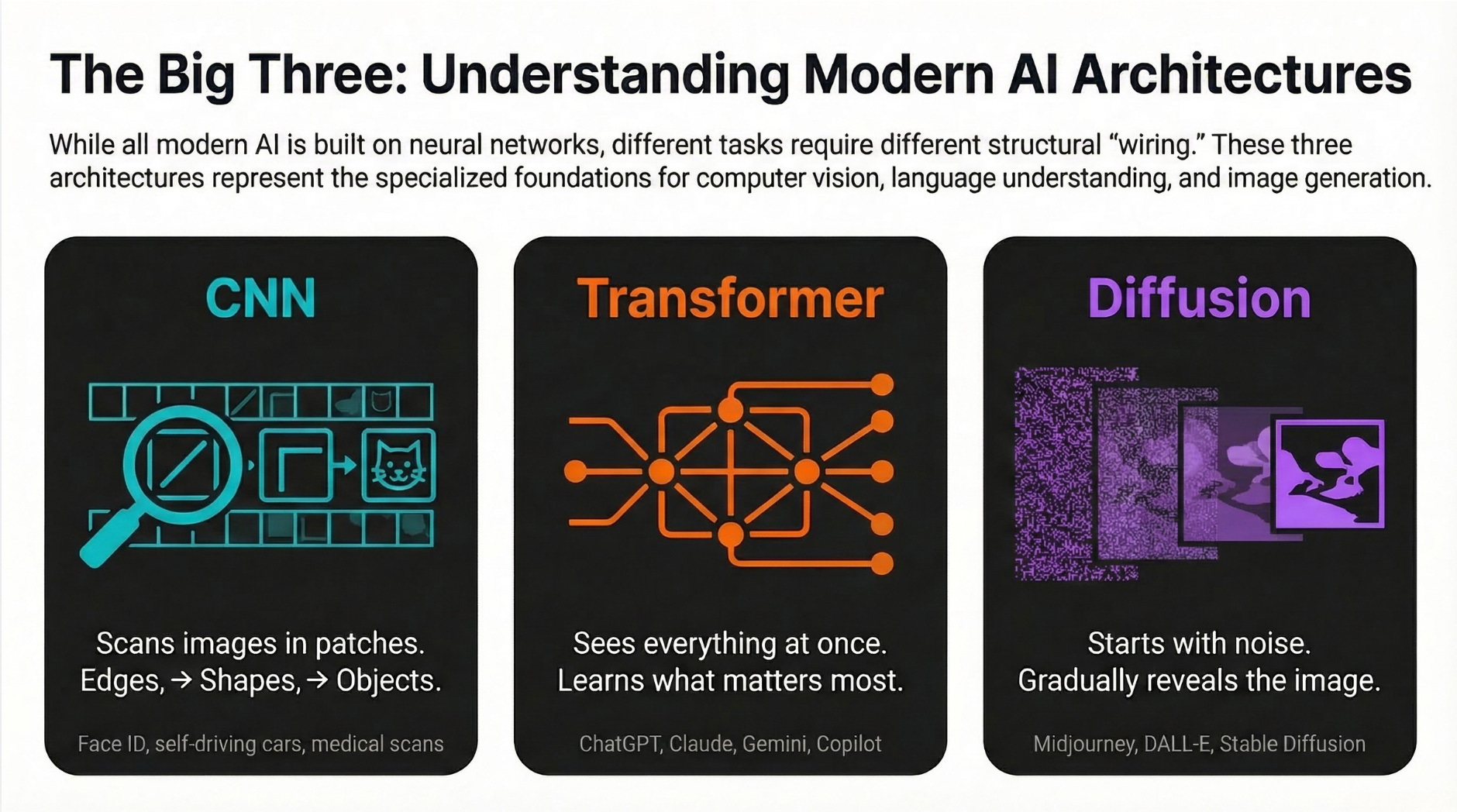
Transformers: The Architecture Behind Everything Big
This is the breakthrough that changed AI. Instead of reading data one piece at a time, Transformers look at the whole thing at once and learn what to pay attention to. That’s why they’re so good at understanding context. They don’t just see the word, they see how it relates to every other word around it.
You use this: ChatGPT, Claude, Gemini, Google Translate, GitHub Copilot. And increasingly, image and video AI too.
Diffusion Networks: The Artists
These networks start with pure random noise (think TV static) and gradually “un-blur” it into a real image. They learn by practicing the reverse: taking a real image, adding noise step by step until it’s unrecognizable, then learning how to reverse that process.
You use this: Midjourney, DALL-E, Adobe Firefly, Stable Diffusion, Sora.
Despite their differences, all three architectures are built on the same foundation: layers of simple units adjusting their weights through feedback to recognize and create patterns. The specialization is in how they’re wired, not what they’re made of.
The honest 2026 picture: Transformers dominate. They’ve quietly taken over text, code, and increasingly images and video. If you hear about a major new AI product, there’s a good chance a Transformer is at the center of it.
The Limitations (Keeping It Real)
Great tools deserve honest assessments. Neural networks are not magic.
They need a huge amount of examples.
A child can learn to recognize a cat from 5 photos. A neural network might need 10,000. The more complex the task, the more data required. This is why big tech companies hoard data. It’s the raw material for their models.
They’re black boxes.
Ask a neural network why it classified that email as spam, and it can’t tell you. It just did. This is a serious problem in medicine, law, and anywhere decisions need to be explainable. Researchers are actively working on “explainable AI” to solve this.
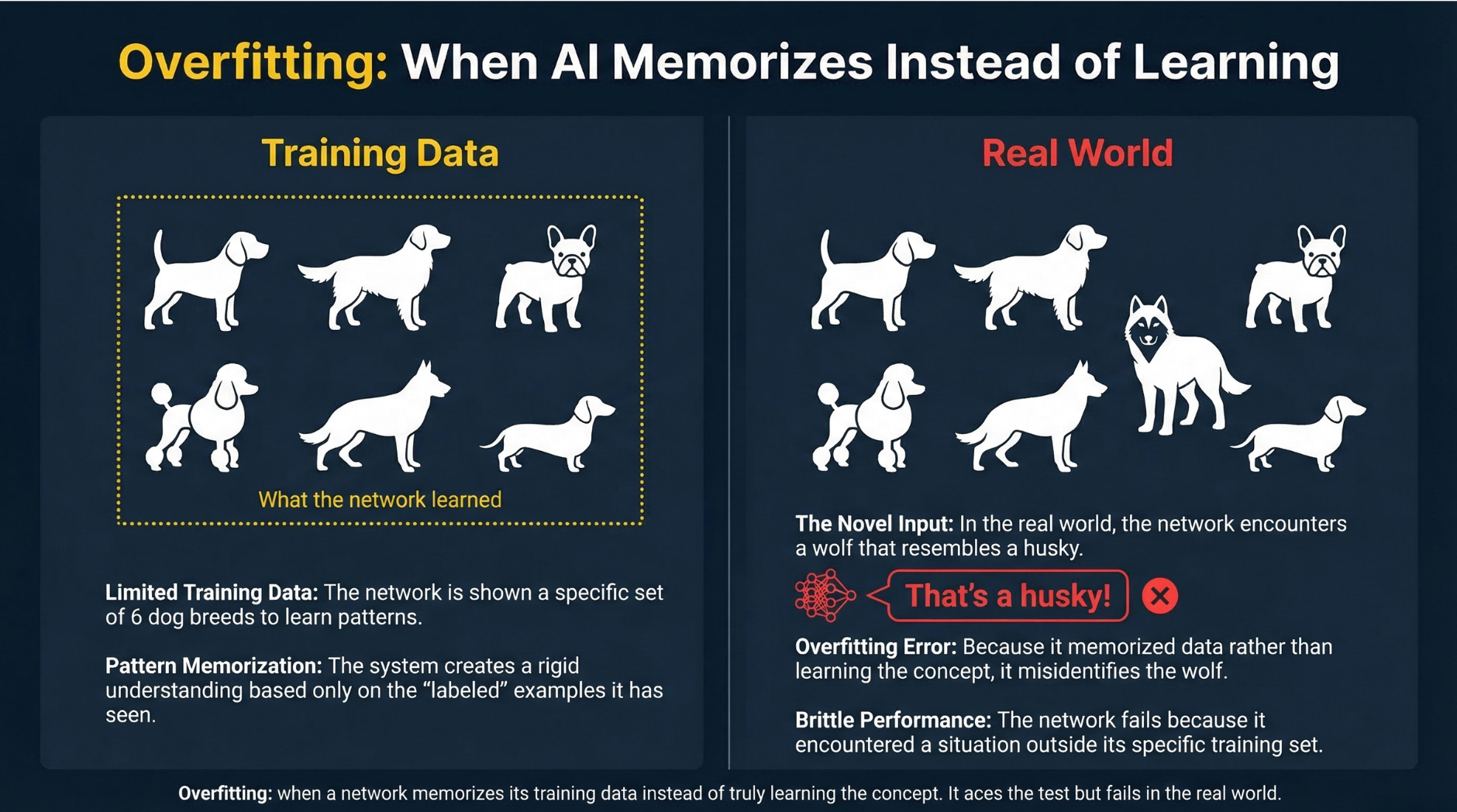
They’re brittle in weird ways.
A neural network trained on millions of dog photos might confidently call a wolf a “husky” because wolves didn’t appear in its training data. This is called overfitting: the network becomes so tuned to what it’s already seen that it stumbles on anything new or slightly different. It’s why testing a model on fresh, unseen examples matters so much. Neural networks are pattern-matchers, not reasoners, and they fail in surprising ways when they encounter situations outside their training.
They’re expensive to train.
Training GPT-4 reportedly cost over $100 million and consumed electricity comparable to running thousands of homes for months. This is a real constraint, and not everyone can build or fine-tune large models.
But here’s what’s changing: a technique called transfer learning means you can take a massive pre-trained network that already understands general concepts (like what an edge, a texture, or a face looks like) and fine-tune it with a smaller amount of your specific data. It’s like teaching a seasoned expert a new specialty instead of training a complete beginner from zero. You don’t always need to start from scratch.
Try It Yourself
Want to feel neural network learning in action? Try this:
-
Go to Teachable Machine by Google (free, no code)
-
Click “Get Started” then “Image Project”
-
Create two classes (e.g., “thumbs up” and “thumbs down”)
-
Show your webcam 30-50 examples of each
-
Click “Train Model” and watch accuracy climb in real time
-
Test it live. Hold up your hand and see the neural network classify it
You just trained a neural network. What you watched happen (the accuracy rising as more examples were added) is gradient descent adjusting weights in real time.
The Takeaway
A neural network is a system of layers connected by weights. It learns by:
-
Making a prediction
-
Measuring how wrong it was (loss)
-
Adjusting its weights to be less wrong (gradient descent)
-
Repeating millions of times
The nonlinear “activation function” between layers (as simple as “replace negatives with zero”) is what gives it the power to learn complex patterns, not just straight lines.
The more layers, the more complex the patterns. That’s deep learning.
And that’s the system behind every AI product you use today, from the one that recognizes your face to the one that writes essays, composes music, and generates videos from a single sentence.
Coming Up
Now that you know what a neural network is, the next question is: what happens when you build one that’s massive, trained on essentially all the text ever written on the internet?
Next up: Large Language Models (LLMs), the specific technology powering ChatGPT, Claude, and Gemini, explained for normal people.
AI for Common Folks — Making AI understandable, one concept at a time.
Leave a Reply